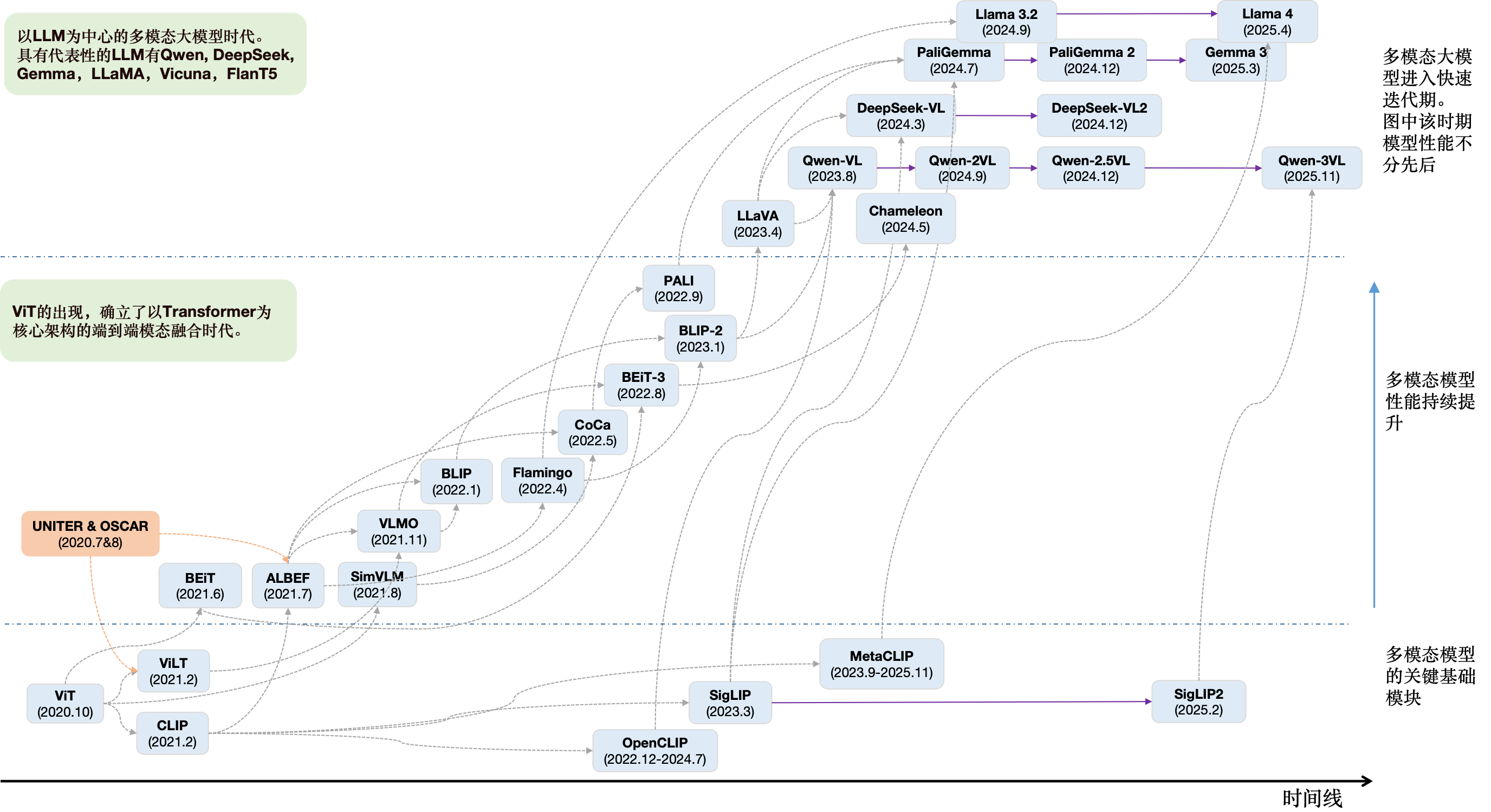
MLLM技术发展脉络(2020-2025)
1. 引言
视觉-语言预训练(Vision-Language Pre-training, VLP)旨在学习视觉与语言两种模态的统一表征,是多模态人工智能领域的核心研究方向。从2017年至2025年,VLP技术经历了三次深刻的范式变革:从依赖外部目标检测器的双流/单流融合架构,到基于Vision Transformer的端到端对比预训练,再到以大语言模型(LLM)为核心的多模态大模型时代。每一次范式的跃迁都带来了表征学习能力的质变,推动VLP模型从特定下游任务的微调适配,逐步走向通用化、多任务化与规模化。
目标检测器驱动的多模态融合时代(2017—2020)。
- 早期VLP模型普遍依赖Faster R-CNN等预训练目标检测器提取图像区域特征,再将区域特征与文本表示输入Transformer进行跨模态融合。这一阶段的代表性工作聚焦于探索视觉-语言交互的架构设计:
- ViLBERT提出双流共注意力Transformer架构,语言流与视觉流通过共注意力层实现深层交互;LXMERT进一步拓展为三编码器架构,引入独立的物体关系编码器与跨模态编码器,并设计了五种预训练任务以学习细粒度模态对齐;
- UNITER则转向单流Transformer架构,以条件掩码策略与最优传输词-区域对齐(WRA)提升跨模态对齐精度;OSCAR另辟蹊径,利用对象标签作为语义锚点,通过三元组表示(词元、对象标签、区域特征)将视觉语义显式注入预训练过程。尽管这些模型在视觉问答、图文检索等任务上取得了显著进展,但其对外部检测器的依赖导致推理速度受限,且区域级特征难以捕捉图像的全局语义。
端到端多模态融合时代(2021—2022)。
- 随着Vision Transformer(ViT)的提出,图像被统一表示为序列化的patch嵌入,为VLP的端到端训练奠定了基础。
- CLIP开创性地采用双编码器对比预训练范式,在4亿图文对上学习对齐的视觉-语言表示,实现了强大的零样本分类能力。SigLIP及其后续版本SigLIP 2进一步优化对比学习目标,以Sigmoid损失解耦批次大小与任务定义的依赖,并通过统一训练配方(结合LocCa解码器、自蒸馏、掩码预测与ACID数据)将语言覆盖扩展至109种语言,同时支持可变分辨率处理。
- 在架构层面,ViLT完全摒弃CNN和区域监督,首次实现纯Transformer的VLP;ALBEF提出"先对齐后融合"策略,配合动量蒸馏分离对齐层与融合层;VLMO设计多路Transformer(MOME),引入模态专属前馈网络专家实现参数高效的多模态学习;BLIP提出多模态编码器-解码器(MED)架构与CapFilt数据引导机制,有效提升数据质量与生成能力;
- Flamingo开创冻结大语言模型结合门控交叉注意力层的少样本学习范式;CoCa以解耦解码器统一对比学习与生成式描述任务;BEiT-3通过Multiway Transformer实现掩码数据建模的统一框架。
- 在规模化与多语言方向,PaLI系列(PaLI、PaLI-X、PaLI-3)系统探索了模型与数据的联合缩放,从17B参数的mT5+ViT-e架构到55B参数的ViT-22B+UL2-32B,再到5B参数的SigLIP对比预训练"小即是美"方案,逐步确立了多语言视觉-语言理解的标杆。
以LLM为核心的多模态大模型时代(2023—2025)。
- 2023年起,VLP研究的重心转向如何将视觉能力高效接入预训练的大语言模型。BLIP-2提出Q-Former作为可学习的桥接模块,在两阶段训练中连接冻结的视觉编码器与冻结的LLM,开启了"冻结LLM + 可学习桥接"的新范式。
- LLaVA则开创了视觉指令微调范式,通过简单的线性投影层将ViT特征映射至LLaMA/Vicuna的嵌入空间,引爆了开源多模态大语言模型(MLLM)的研究热潮。以Qwen-VL为代表的MLLM进入了快速迭代期间。
- Qwen-VL系列展现了清晰的迭代脉络:Qwen-VL采用Q-Former风格适配器与三阶段训练;Qwen2-VL引入动态分辨率ViT、Patch Merger与M-RoPE位置编码;Qwen3-VL进一步升级为SigLIP2视觉编码器、DeepStack特征聚合与交错M-RoPE。
- Llama系列从3.2 Vision的ViT-H/14+门控交叉注意力视觉适配器,演进至Llama 4的MoE架构(17B激活/400B总参数)与早期融合策略。
- DeepSeek-VL系列同样呈现了快速迭代:DeepSeek-VL采用SigLIP-L+SAM-B混合视觉编码器与两层混合MLP适配器,通过模态平衡训练(70% VL + 30%文本)实现视觉-语言能力的协调;DeepSeek-VL2进一步引入动态分块视觉编码(SigLIP-SO400M)、MoE与MLA注意力机制,提供Tiny(3B)、Small(16B)、Base(27B)三规模版本。
- PaliGemma系列则以轻量高效为特色:PaliGemma将SigLIP与Gemma-2B结合实现3B参数的高效模型;Gemma 3支持128K上下文窗口与Pan and Scan视觉处理;PaliGemma 2则升级为SigLIP2+Gemma 2架构,延续了PaLI系列的技术传统。
本报告系统梳理2017年至2025年间视觉-语言预训练领域的技术演进脉络,重点围绕上述三大范式转变展开:从依赖检测器的特征融合(ViLBERT、LXMERT、UNITER、OSCAR),到端到端的多模态融合(CLIP、BEiT、BLIP、PaLI系列等),再到以大语言模型为核心的多模态大模型时代(BLIP-2、LLaVA、Qwen-VL、DeepSeek-VL、PaliGemma系列等)。报告剖析各阶段代表性模型的架构设计、预训练策略与技术贡献,阐明模型间的技术承接关系与演进逻辑,为希望了解MLLM发展脉络的同学提供技术参考与范式洞察。
2. 目标检测器驱动的视觉语言预训练(2017—2020)
随着BERT等预训练语言模型的兴起,研究者开始探索视觉-语言预训练(Vision-Language Pre-training, VLP)方法。这一时期的典型特征是使用预训练的目标检测器(如Faster R-CNN)提取图像的区域特征,然后与文本特征进行融合。
2.1 ViLBERT与LXMERT:双流架构的探索
在视觉-语言预训练领域,双流架构是一种重要的设计范式,其核心思想是为视觉和语言模态分别设置独立的编码流,再通过特定的机制实现跨模态信息交互。ViLBERT和LXMERT是这一范式的两个代表性工作,它们均在2019年下半年发表,奠定了双流架构在VLP中的基础地位。
2.1.1 ViLBERT:预训练任务无关的视觉语言学表示
发布时间: 2019年8月(arXiv:1908.02265)/ NeurIPS 2019(2019年12月,温哥华)[x]
作者与机构: Jiasen Lu(Georgia Tech)、Dhruv Batra(Georgia Tech & Facebook AI Research)、Devi Parikh(Georgia Tech & Facebook AI Research)、Stefan Lee(Oregon State University)
核心贡献: ViLBERT(Vision-and-Language BERT)提出了双流架构来处理视觉-语言任务。该模型由两个并行的BERT风格编码流组成——一个用于处理文本输入(语言流),另一个用于处理图像输入(视觉流)。两个编码流分别由多个标准的Transformer编码器块(TRM)和**共注意力Transformer层(Co-TRM)**交替堆叠而成,其中Co-TRM是ViLBERT的核心创新,它通过跨模态的双向注意力机制实现视觉和语言表示之间的信息交换。
在视觉端,ViLBERT使用预训练的Faster R-CNN(ResNet-101骨干网络)提取图像的区域特征,选取置信度阈值以上得分最高的10至36个检测框作为视觉输入。在语言端,文本流使用预训练的BERT模型进行初始化。ViLBERT在大规模的Conceptual Captions数据集上进行预训练,采用两个自监督预训练任务:(1)掩码多模态建模——同时掩码文本中的词语和图像中的区域特征,要求模型基于可见的跨模态上下文进行预测;(2)多模态对齐——预测文本描述与图像是否匹配。预训练后的ViLBERT可以轻松迁移到VQA、视觉常识推理(VCR)、指代表达定位(Grounding Referring Expressions)、基于标题的图像检索等多个下游任务,并在当时取得了领先性能。
2.1.2 LXMERT:基于Transformer的跨模态编码表示学习
发布时间: 2019年8月(arXiv:1908.07490)/ EMNLP 2019
作者与机构: Hao Tan、Mohit Bansal(UNC Chapel Hill)
核心贡献: LXMERT(Learning Cross-Modality Encoder Representations from Transformers)同样采用双流架构,但在模型设计和预训练策略上进行了重要创新。与ViLBERT相比,LXMERT引入了更细粒度的三编码器架构:(1)物体关系编码器——使用5层Transformer处理图像中的物体区域特征,建模物体间的关系;(2)语言编码器——使用9层Transformer处理文本输入;(3)跨模态编码器——使用5层跨模态Transformer层,每层包含双向交叉注意力子层(从语言到视觉和从视觉到语言两个方向)和两个自注意力子层,实现深层跨模态交互。
LXMERT设计了五个多样化的预训练任务:(1)掩码跨模态语言建模——利用视觉信息辅助预测被掩码的词;(2)掩码物体预测中的RoI特征回归——基于可见上下文预测被掩码物体的特征表示;(3)掩码物体预测中的检测标签分类——预测被掩码物体的类别标签;(4)跨模态匹配——判断图像和句子是否匹配;(5)图像问答——利用数据集中的问答对进行预训练。这种多任务预训练策略使模型既能学习单模态内的结构关系,也能学习跨模态的对齐关系。
LXMERT在预训练后仅需添加简单的任务特定分类层进行微调。实验表明,LXMERT在VQA和GQA数据集上取得了当时的最优性能,并且在NLVR2(自然语言视觉推理)挑战上将此前最优结果大幅提升了22个百分点(从54%提升至76%),充分证明了其预训练表示的强大泛化能力。此外,LXMERT是当时唯一同时在VQA和GQA两个挑战赛的90多支参赛队伍中均进入前三的方法。
2.2 UNITER:单流架构的统一表达学习
发布时间: 2020年7月(ECCV 2020)
核心贡献:
- 单流(Single-Stream)Transformer架构:将所有视觉和文本token拼接后输入单一Transformer,实现更深度的跨模态融合,参数量远小于双流模型
- 条件掩码(Conditional Masking)策略:每次只mask一个模态而保持另一个模态完整,避免了联合随机掩码可能导致的模态不对齐问题
- 基于最优传输的词-区域对齐(WRA):引入Optimal Transport理论,显式地鼓励单词和图像区域之间的细粒度对齐,是UNITER的核心创新
- 通用表示能力:在六个视觉-语言任务(九个数据集)上均达到SOTA,展现了强大的通用性
模型架构:
UNITER采用单流架构,由三个核心组件组成:
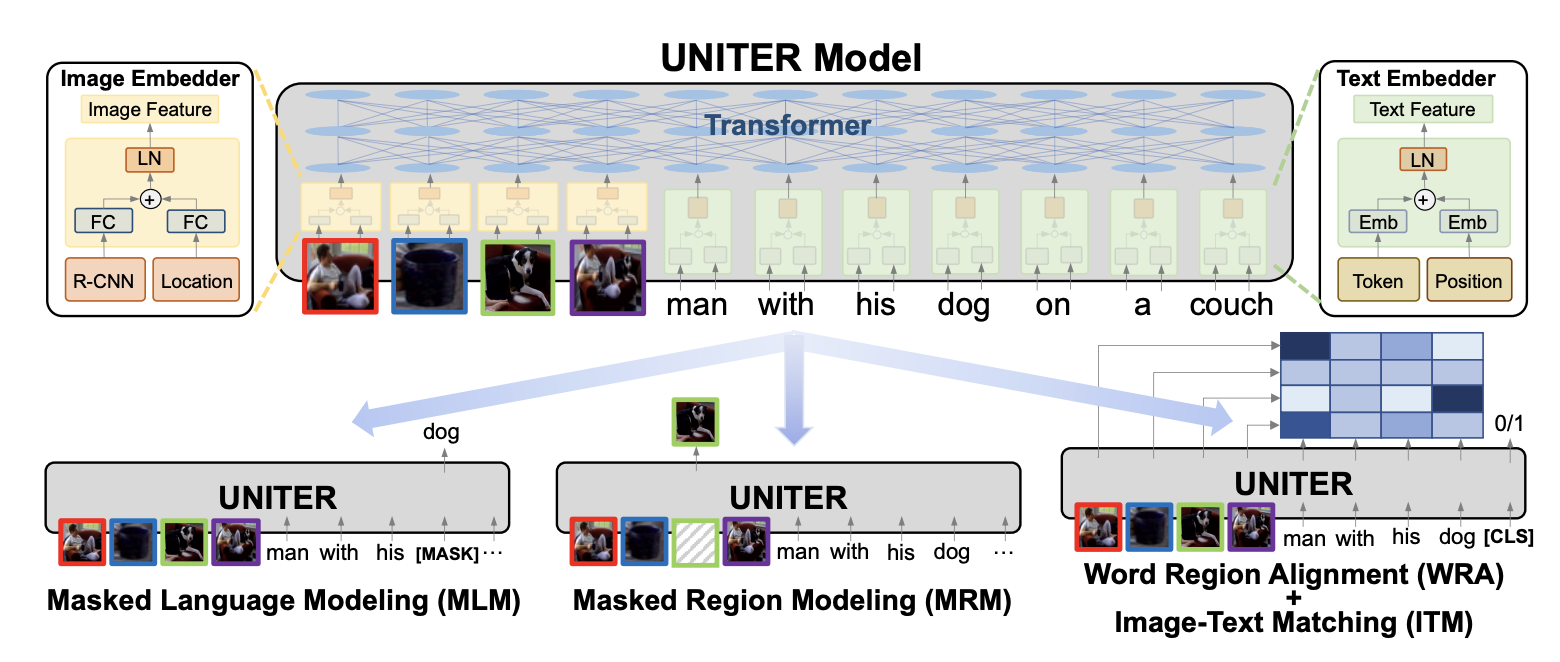
-
Image Embedder(图像嵌入器)
- 使用Faster R-CNN(在Visual Genome目标+属性数据上预训练)提取每个图像区域的视觉特征
- 视觉特征维度:2048-d(pooled RoI特征)
- 位置编码:使用7维向量 ,包含归一化的左上角坐标 、右下角坐标 、宽度 、高度 、面积
- 视觉特征和位置特征分别通过全连接层投影到同一嵌入空间后相加,再经层归一化得到最终视觉嵌入
-
Text Embedder(文本嵌入器)
- 使用BERT的WordPiece tokenizer将输入句子分词
- 每个sub-word token的表示 = 词嵌入 + 位置嵌入 + 模态嵌入(modality embedding,帮助模型区分视觉和文本输入)
- 通过层归一化得到最终文本嵌入
-
多层级Transformer
- 视觉嵌入和文本嵌入拼接后输入统一的Transformer
- 自注意力机制无序地作用于所有token,因此需要显式位置编码
架构参数汇总:
| 参数 | UNITER-base | UNITER-large |
|---|---|---|
| Transformer层数 | 12 | 24 |
| 隐藏维度 | 768 | 1024 |
| 注意力头数 | 12 | 16 |
| 总参数量 | 86M | 303M |
| 预训练GPU小时 | 882 V100小时 | 3645 V100小时 |
UNITER-base以86M参数(约为ViLBERT 221M的39%、LXMERT 183M的47%)在所有下游任务上超越了两者,充分证明了单流架构的参数效率优势。
预训练任务:
UNITER共设计了四个主要预训练任务,在每次训练迭代中随机采样其中一个任务进行更新:
1. MLM(Masked Language Modeling,以图像为条件)
- 随机mask约15%的文本token(替换为
[MASK]) - 模型根据完整的图像和未mask的文本预测被mask的token
- 关键设计:每次只mask一个模态,保持另一个模态完整
2. MRM(Masked Region Modeling)— 三种变体
对图像侧,随机mask约15%的区域(将视觉特征向量替换为全零),模型需要预测被mask区域的内容。每次保持文本模态完整。
- MRFR(Masked Region Feature Regression):用线性层将Transformer输出投影到与Faster R-CNN视觉特征相同的维度,以L2损失回归被mask区域的原始视觉特征:
-
MRC(Masked Region Classification):用线性分类器预测被mask区域的语义类别,使用Faster R-CNN预测的物体类别作为伪标签,损失函数为交叉熵损失
-
MRC-kl(Masked Region Classification with KL-Divergence):使用软标签替代MRC的硬标签,使UNITER对被mask区域的预测分布尽可能接近Faster R-CNN的预测分布:
3. ITM(Image-Text Matching,图文匹配)
- 学习图像和句子之间的实例级对齐
- 训练时以50%概率将图文对中的句子替换为不匹配句子
- 使用
[CLS]token的输出通过线性层预测图文是否匹配 - 损失函数:二分类交叉熵
4. WRA(Word-Region Alignment,词-区域对齐)— 核心创新
WRA是UNITER最具创新性的预训练任务,通过**最优传输(Optimal Transport, OT)**理论显式鼓励单词和图像区域之间的细粒度对齐。
数学描述:
将词token的嵌入集合 和图像区域的嵌入集合 看作两个离散概率分布 和 。WRA目标是最小化将图像区域分布传输到词分布的总代价:
其中:
- 和 分别是文本token和图像区域的离散概率分布
- 和 是两个分布的边际分布(通常取均匀分布)
- 是所有满足边际约束的联合分布(传输计划)集合
- 是传输矩阵的元素,表示从区域 到词 的传输量
- 是代价函数,定义为两个嵌入之间的余弦距离
通过最小化传输代价,模型学习到最优的词-区域对应关系。WRA使用Inexact Proximal point method for OT(IPOT)算法求解传输矩阵,由于OT计算开销较大,WRA仅在UNITER-large的预训练中使用。
条件掩码策略:
UNITER的关键设计在于每次只mask一个模态(而ViLBERT和LXMERT采用联合随机mask两个模态)。
设计动机:如果同时随机mask一个区域和描述该区域的词,模型面临"双重缺失"问题——被mask的区域和被mask的词同时不可见,导致模型被迫从噪声信号中学习,难以正确建立跨模态对齐。
实验验证:在消融实验中,条件掩码策略(Meta-Sum=399.97)显著优于联合随机掩码(Meta-Sum=396.51),证明了该策略的有效性。
训练数据:
| 数据集 | 类型 | 规模 |
|---|---|---|
| COCO | In-domain 图像标题 | ~113K图像, ~0.57M对 |
| Visual Genome | In-domain 密集标题 | ~108K图像, ~5.0M对 |
| In-domain合计 | ~5.6M训练对 | |
| Conceptual Captions (CC) | Out-of-domain | ~3.3M对 |
| SBU Captions | Out-of-domain | ~0.86M对 |
最优训练策略采用两阶段预训练:先在In-domain数据(COCO + VG)上预训练,再在Out-of-domain数据(CC + SBU)上继续训练。
与历史模型的关系:
- 与ViLBERT/LXMERT:UNITER从根本上改变了架构范式——从双流转向单流。ViLBERT和LXMERT认为双流架构更优,但UNITER证明在合适的预训练设置下,单流模型可以用更少的参数达到更强性能(UNITER-base 86M vs ViLBERT 221M vs LXMERT 183M)
- 与BERT:UNITER-base和UNITER-large的架构设计直接对应BERT-BASE和BERT-LARGE,继承了BERT的预训练思想和参数配置
- 与OSCAR(同期):UNITER和OSCAR同为ECCV 2020单流模型,但UNITER通过条件掩码和WRA实现了更优的性能;OSCAR则以物体标签作为锚点进行对齐
- 技术定位:UNITER标志着VLP领域从"双流时代"进入"单流时代",其条件掩码和最优传输对齐思想影响了后续BLIP、ALBEF等模型的设计
技术影响:
- 单流范式的确立:UNITER的实验结果有力地证明了单流架构在参数效率和性能上的双重优势,推动了后续ViLT、SimVLM等模型采用单流设计
- 条件掩码策略的启发:每次只mask一个模态的思想被后续模型广泛借鉴,成为避免跨模态信息泄露的标准实践
- 最优传输在多模态中的应用:WRA将Optimal Transport理论引入视觉-语言对齐,开创了基于结构化对齐的预训练新方向
- 轻量高效模型标杆:UNITER-base以86M参数在六个任务上达到SOTA,证明了精心设计的小模型可以超越盲目堆叠参数的大模型
2.3 OSCAR:目标语义对齐预训练(2020年8月)
OSCAR: Object-Semantics Aligned Pre-training for Vision-Language Tasks由Li等人于2020年8月提出(ECCV 2020发表)[^16],来自微软研究院和华盛顿大学。
核心贡献: OSCAR是检测器驱动VLP时代的重要里程碑。OSCAR的核心创新在于利用对象标签(Object Tags)作为锚点,桥接视觉和语言模态之间的语义鸿沟。OSCAR在图像描述生成、VQA、图像-文本检索等六个下游任务上创造了新的最优性能,相比UNITER等同期模型在图像-文本检索任务上提升了3-5个百分点。
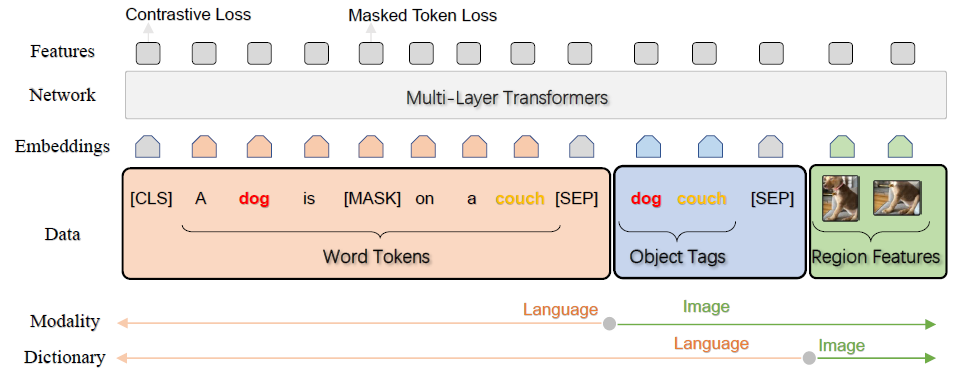
图2:OSCAR模型架构。OSCAR将每个图像-文本对表示为三元组(Word Tokens, Object Tags, Region Features),其中检测到的目标标签(如"dog"、“couch”)作为连接语言和视觉模态的语义锚点。
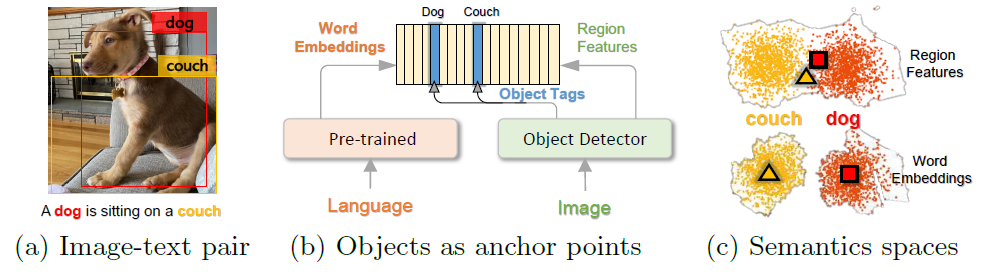
图3:OSCAR中目标标签作为语义锚点的示意图。图像中的显著目标(狗、沙发)被检测器识别为标签,这些标签在语义空间中与对应词嵌入天然对齐,从而将图像区域特征与文本词汇关联起来。
模型架构:OSCAR将每个图像-文本对表示为一个三元组(word tokens, object tags, region features)。
-
word tokens是文本描述经过BERT分词后的词嵌入序列,以[CLS]开头,[SEP]结尾。
-
object tags预训练目标检测器(如Faster R-CNN)检测到的图像中对象的类别标签(如"dog"、“person”、“couch”)的词嵌入序列——这是OSCAR的核心创新。
-
region features是检测到的图像区域的特征向量。这三个部分共同输入一个多层Transformer编码器。
核心思想:OSCAR的设计基于一个关键观察——图像中的显著目标通常也会被文本描述所提及。由于目标标签和文本都是语言形式的(均为单词),它们之间的对齐相对容易学习,而这些目标标签对应的图像区域因此更容易与相关文本词汇建立关联。
预训练任务:
(1) 掩码token建模(Masked Token Loss):随机遮蔽输入序列中的部分词token,让模型预测被遮蔽的token。
(2) 对比学习(Contrastive Loss):对输入的三元组进行打乱或替换,让模型判断三元组是否匹配。
技术影响: OSCAR证明了利用对象标签作为语义锚点能够显著提升视觉-语言表示的对齐质量。在当时的多个下游任务上取得了最先进的结果,包括图像-文本检索(Image-Text Retrieval)、视觉问答(VQA)、自然语言视觉推理(NLVR2)和图像描述生成(Image Captioning)。然而,OSCAR严重依赖预训练目标检测器的质量,且检测过程计算代价高昂,限制了其可扩展性。
与历史模型的关系:OSCAR属于VLP时代的工作,与同期的ViLBERT(双流架构)和UNITER(单流架构)相比,OSCAR的独特之处在于引入了目标标签作为语义锚点。OSCAR使用Faster R-CNN提取区域特征的方式继承了Bottom-Up-Top-Down (BUTD) 的思想。
3. 端到端多模态融合(2021—2022)
2021年是Image-to-Text乃至整个视觉-语言领域的分水岭年份。Vision Transformer(ViT)的成功催生了无需目标检测器的端到端Vision-Language Pretraining (VLP) 方法。同时,通过对比学习(Contrastive Learning)在大规模图像-文本对数据上训练得到的视觉-语言模型在图文检索上的强大能力被CLIP充分验证,开启了视觉-语言基础模型的新纪元。
在这期间,研究开始集中在如何设计更有效的多模态特征融合框架和训练方法。主流的研究工作可以分为4个方向(他们也相互交织):
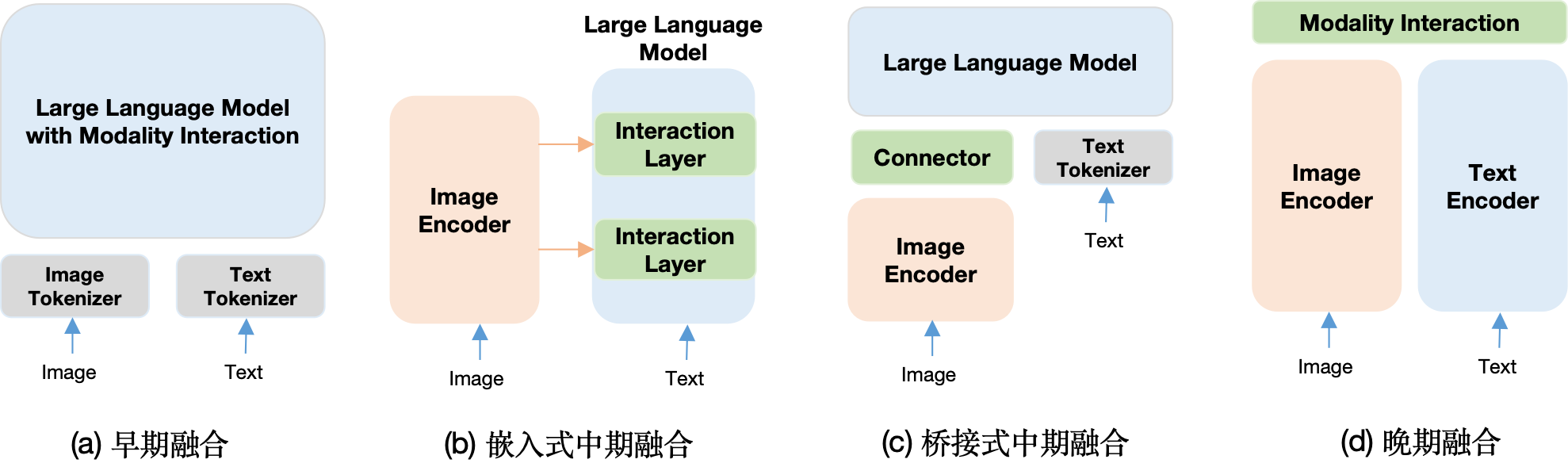
(a) 早期融合。早期融合的特点有:
- 无预训练视觉编码器
- 图像不经过视觉编码器
- 所有模态(e.g., 文本和图像)以token的方式从模型的第1层就参与融合
代表模型:ViLT,BEiT,BEiT-3,VLMO 等
(b) 嵌入中期融合
- 图像会经过独立的(深层)视觉编码器
- 视觉编码器的中间层输出或者最后层输出会输入到LLM中的多模态融合层
- 多模态融合层可以通过可训练的模块(比如cross-attention module)来融合多模态特征。
- 多模态融合层也可以通过直接拼接多模态特征的方式来融合多模态特征。
- "融合"发生在视觉编码器之后、LLM之中
代表模型: ALBEF,BLIP,Famingo,CoCa,
© 桥接式中期融合
- 图像先经过独立的(深层)视觉编码器
- 视觉编码器输出通过一个连接器(Connector)对齐到LLM的特征空间
- "融合"发生在视觉编码器之后、LLM之前。多模态数据的特征通过连接器进行融合。
代表模型: SimVLM,BLIP-2,PALI等
(d) 晚期融合。晚期融合的特点有:
- 各模态有完全独立的处理路径
- 仅在最后阶段进行简单融合
代表模型:CLIP,SigLIP,MetaCLIP 等
3.1 ViT: Vision Transformer
An image is worth 16x16 words: transformers for image recognition at scale 由google brain团队在ICLR 2021上发表。
核心贡献:
- ViT是将transformer应用于视觉领域并在大规模图片数据上进行训练的开山之作,催生了无需目标检测器的端到端VLP方法。
- ViT虽然在原论文中只用于对图片的分类。但是,ViT使单一transformer模型能够同时处理原始文本和(patchify后)图像数据成为了可能,为原生多模态模型的发展奠定了基础。
- ViT在多个图像分类数据集上达到甚至超越了SOTA水平,同时其预训练成本相对较低。
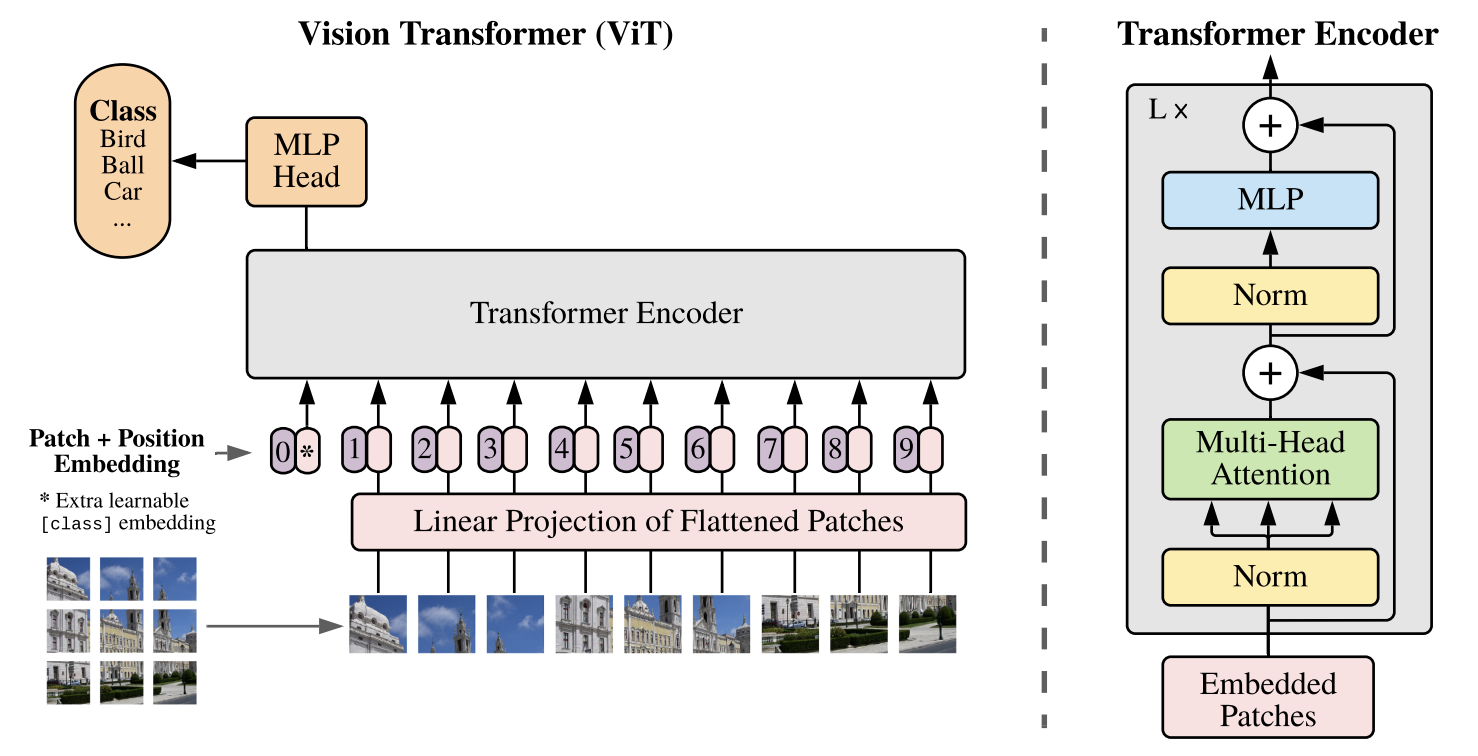
ViT设计思想:尽可能严格地遵循原始 Transformer的架构。这种刻意保持简洁的设计有一个优势:那些可扩展的 NLP Transformer 架构——以及它们的高效实现——几乎可以开箱即用。
ViT图片预处理:ViT一个主要的创新点是在图片预处理上。即如果处理图片,使其能够被Transformer处理:
- 输入图像: (, , 分别是图片的高,宽,通道)
- 切分Patch:将图像切成 个patch,每个patch尺寸为 。图片的维度变化为
- Flatten + 线性投影:将每个patch展平并通过可训练线性层映射为维的Patch Embeddings:
- 添加[CLS] Token:在序列前添加可学习的分类token :
- 添加位置编码:加入1D可学习位置嵌入保留位置信息:
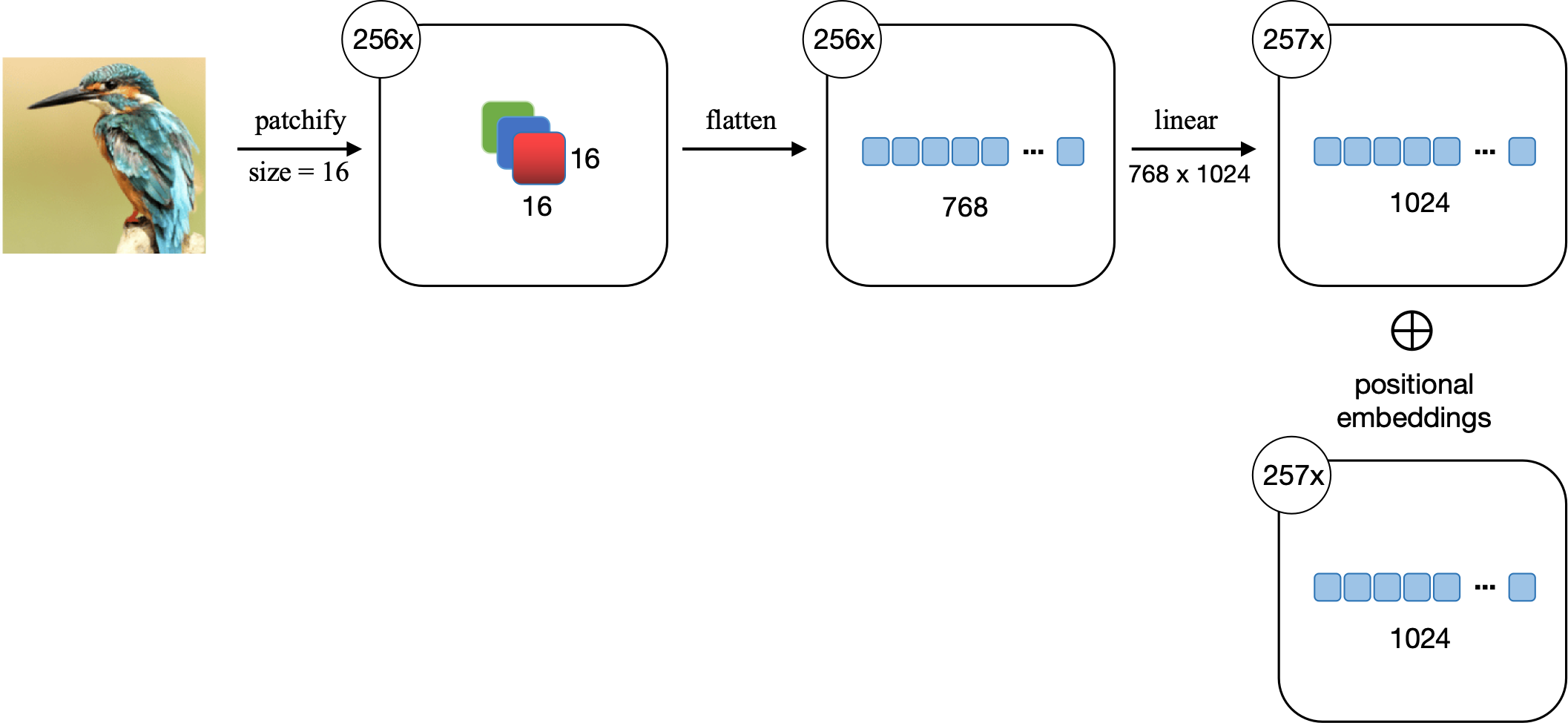
输入图片为256x256x3; patch size为16, 每个patch为16x16x3; 一共有256个patch。对每个patch进行flatten和线性投影,形成一个维度为1024的embedding。256个embedding和1个分类token embedding形成257个embedding。然后在每一embedding上加入positional embedding。
Transformer前向处理:
- 输入Transformer Encoder
- 输出序列说明:,仅 输入分类头
3.2 CLIP:对比语言-图像预训练(2021年2月)
CLIP: Learning Transferable Visual Models from Natural Language Supervision由OpenAI于2021年2月发布(ICML 2021发表),是视觉-语言领域最具革命性的工作之一。
核心贡献:
- CLIP(Contrastive Language-Image Pre-training)是视觉-语言基础模型领域的里程碑式工作。CLIP证明了使用大规模图片文本对数据进行训练可以学习可迁移的视觉表征,其零样本(Zero-shot)泛化能力在当时令人惊叹。
- CLIP及其改进工作成为了多模态大模型中进行模态对齐的核心模块。
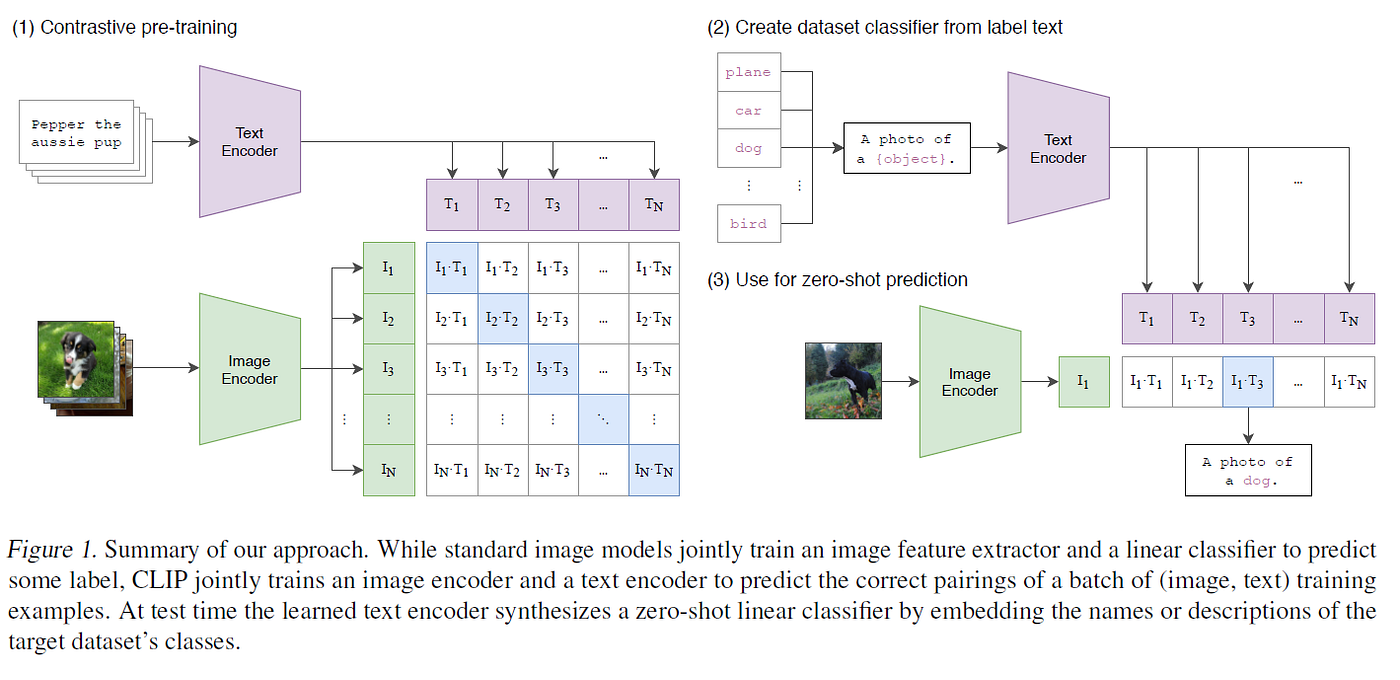
图4:CLIP模型架构(来自OpenAI论文原图)。左侧为对比预训练阶段:图像编码器和文本编码器分别将图像和文本映射到联合嵌入空间,通过对比损失学习对齐。右侧为零样本预测阶段。
模型架构:CLIP的架构包含两个独立但对称的编码器。
-
视觉编码器支持Vision Transformer(ViT-B/32、ViT-B/16、ViT-L/14等)和修改后的ResNet。ViT变体将图像分割为固定大小的Patches,通过线性嵌入和位置嵌入后输入Transformer编码器。采用特殊[CLS]令牌对应的最终隐藏状态作为全局图像表示。
-
文本编码器是12层Transformer,以[SOS]开头、[EOS]结尾。[EOS]标记的最终隐藏状态作为文本嵌入。
-
两个编码器输出的嵌入向量经过投影层映射到相同维度,并通过L2归一化。
对比训练目标:对于一个包含个图像-文本对的训练批次( 为 batch size, e.g., 32768),CLIP构建一个的余弦相似度矩阵,对角线元素为正样本对,非对角线元素为负样本对。训练目标是对每个图像和每个文本分别进行交叉熵分类优化:
其中 , 为可学习温度系数。
loss关键特征:
- 全局归一化:每个样本的 loss 计算必须依赖 batch 内所有其他样本的相似度(softmax 分母需遍历整列/整行)。
- N 选 1 的多分类:对第 张图而言,个文本构成一个竞争池,模型必须从中选出正确的那一个。
- 双向对称:需要分别计算图像→文本和文本→图像两个方向的交叉熵并取平均 。
数据集: CLIP在一个包含 4亿对(Image, Text) 的大规模数据集上进行训练,该数据从互联网收集而来。
技术影响: CLIP的革命性贡献包括:
- 零样本分类: 通过将类别名称转换为文本描述(如"a photo of a {label}"),CLIP可以无需任何训练样本直接对图像进行分类,在ImageNet上的零样本准确率达到了76.2%。
- 可迁移性: CLIP学到的视觉表示可以迁移到广泛的下游任务,包括图像-文本检索、目标检测、语义分割等。
- 开放词汇能力: 由于使用自然语言进行监督,CLIP可以识别训练时未见过的类别。
- 基础模型范式: CLIP开创了视觉-语言基础模型的研究范式,后续大量工作以其为基础进行扩展和改进。
零样本能力:CLIP可以在没有任何下游任务特定训练的情况下执行图像分类、图像-文本检索等任务。在ImageNet上的零样本分类性能达到了与完全监督训练的ResNet-50相当的水平。
与历史模型的关系:
- CLIP受到ViLBERT、UNITER、OSCAR等VLP模型的启发,但采用了截然不同的训练范式——抛弃复杂的MLM和ITM任务,仅使用简单的对比损失在海量数据上训练。CLIP的视觉编码器成为后续几乎所有多模态大语言模型的标准视觉骨干网络。
- CLIP的局限性在于其双编码器架构缺乏深层次的跨模态交互,不适合需要细粒度视觉推理的任务(如Visual Question Answering,Visual Reasoning, Visual Entailment)。这促使研究者探索如何结合对比学习和融合编码器的优势。
3.3 SigLIP:基于Sigmoid损失的对比语言-图像预训练(2023年3月)
Sigmoid Loss for Language Image Pre-Training由Google DeepMind的Xiaohua Zhai、Basil Mustafa、Alexander Kolesnikov和Lucas Beyer于2023年3月发布(ICCV 2023 Oral发表),是对CLIP训练范式的根本性改进。
核心贡献:
- SigLIP的核心创新在于用逐对Sigmoid损失(pairwise sigmoid loss)替代CLIP中基于全局批次归一化的Softmax对比损失。这一改动带来了三个关键优势:
- (1) 每个图像-文本对被独立处理为二元分类问题,无需在全局批次上进行Softmax归一化,大大简化了分布式训练的实现;
- (2) 在概念上将批次大小(batch size)与任务定义解耦,使得在较小批次下也能获得良好的训练效果;
- (3) Sigmoid实现比Softmax损失需要更少的内存,支持更大批次的训练。实验表明,当批次大小小于16k时,Sigmoid损失的表现显著优于Softmax损失;合理的批次大小(32k)即可满足图像-文本预训练需求。
模型架构:SigLIP采用标准的双塔架构(dual-tower architecture),与CLIP类似,包含一个视觉编码器和一个文本编码器,两个编码器分别将图像和文本映射到共享的嵌入空间中。
-
视觉编码器基于标准的Vision Transformer(ViT)架构,使用可学习的位置嵌入。SigLIP提供了从ViT-B/16(~86M参数)到ViT-g/14(~1B参数)的多个变体。输入图像被分割为不重叠的图像块(patch),通过线性投影映射为嵌入向量,经过多层Transformer编码器处理后,不使用CLS token,而是采用**MAP Head(Multihead Attention Pooling)**将patch token序列聚合为单一的图像嵌入表示。
-
文本编码器基于标准的Transformer Encoder架构,使用32k词汇量的SentencePiece分词器(在英语C4数据集上训练),最大文本长度为16个token。与视觉编码器共享相同的MAP Head池化机制。
-
两个编码器输出的嵌入向量被投影到共享的d维嵌入空间中,经过L2归一化(单位范数)。相似度得分通过可学习的温度参数t和偏置项b进行缩放和平移:。
Sigmoid对比训练目标:SigLIP的核心是其Sigmoid对比损失函数。对于批次B中的N个图像-文本对,设为第i个图像的嵌入,为第j个文本的嵌入,则SigLIP损失定义为:
其中:
- 是Sigmoid函数
- 当 (正样本对), 当 (负样本对)
- 是可学习的温度参数,用于缩放相似度
- 是可学习的偏置项,默认初始化
- 默认初始化为 (即 )
偏置项的引入至关重要:训练初期负样本远多于正样本,偏置项确保训练从接近先验分布的位置开始,防止早期优化中负样本主导损失函数。
Sigmoid损失的分布式优势:Sigmoid损失的独立性使得高效的分布式训练成为可能——设每设备批次大小为,通过在不同设备间循环交换表示,每个设备仅需在本地计算损失块。不需要all-gather操作,内存开销从降低到每设备。在4个TPUv4芯片上即可实现批量大小达4096的SigLIP训练(相同硬件下CLIP仅能容纳2048)。SigLiT模型在4个TPUv4芯片上,一天内达到79.7% ImageNet零样本准确率(使用B/8);两天达到84.5%(使用g/14)。
与CLIP的对比:
| 特性 | CLIP (Softmax) | SigLIP (Sigmoid) |
|---|---|---|
| 损失类型 | 全局Softmax归一化对比损失 | 逐对Sigmoid二元分类损失 |
| 归一化范围 | 需要全局批次统计量 | 每对独立处理,无需全局归一化 |
| 分布式实现 | 需要两次all-gather操作 | 仅需一次pass,支持chunked实现 |
| 内存需求 | 相似度矩阵 | 每设备(为本地批次) |
| 小批次(<16k)性能 | 较差 | 显著优于Softmax |
| 批次大小敏感性 | 高度依赖大批次 | 对批次大小更鲁棒 |
| 训练效率 | 较低(需全局归一化) | 更高(内存高效,支持更大批次) |
| 偏置项 | 无 | 有可学习偏置项平衡正负样本 |
数据集: SigLIP在Google内部的WebLI数据集上进行训练,该数据集包含约100亿张图像和120亿个alt-text,覆盖109种语言。SigLIP原始模型主要使用英语图像-文本对进行训练,图像输入尺寸为224×224。
技术影响: SigLIP对视觉-语言预训练领域产生了深远影响:
- 训练效率范式转变:证明了在中小批次(4k-32k)下使用Sigmoid损失比CLIP的Softmax损失更高效且效果更好,降低了高质量视觉-语言模型的训练门槛。
- 后续模型广泛采用:SigLIP的Sigmoid损失被后续众多模型采用,包括LLaVA-OneVision、PaliGemma、Qwen2.5-VL等的视觉编码器,成为视觉-语言预训练的标准选择之一。
- 多语言扩展:基于原始SigLIP训练了支持100+语言的mSigLIP(multilingual SigLIP),拓展了视觉-语言模型的多语言理解能力。
- 理论分析基础:为后续关于Sigmoid对比损失的理论分析提供了重要基准(如全局最小值分析、嵌入空间几何结构等)。
- 直接催生了SigLIP 2:作为SigLIP 2的基础架构和核心技术,推动了视觉-语言编码器的持续演进。
与历史模型的关系:SigLIP继承了CLIP的双塔架构设计理念——分别用视觉编码器和文本编码器将两种模态映射到共享嵌入空间,同时继承了ViT的视觉编码架构和Transformer的文本编码架构。与CLIP最核心的区别在于损失函数的根本变革——用Sigmoid二元分类损失替代Softmax对比损失,实现了批次大小与任务定义的解耦。SigLiT变体还继承了LiT(Locked-image Tuning)的思想,使用预训练的冻结视觉编码器,仅训练文本编码器。SigLIP证明了简单的损失函数改动可以带来训练效率、内存效率和性能的多重提升,为视觉-语言预训练领域开辟了新的优化方向。
3.4 SigLIP 2:多语言视觉-语言编码器与增强语义理解(2025年2月)
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features由Google DeepMind的Michael Tschannen、Alexey Gritsenko、Xiao Wang等人于2025年2月发布(arXiv:2502.14786),是SigLIP的全面升级版本。
核心贡献: SigLIP 2将多个先前独立发展的技术整合到一个统一的训练配方(unified training recipe) 中,主要包括:基于解码器的预训练(LocCa风格的图像描述和定位理解)、自监督损失(自蒸馏和掩码预测)以及在线数据策展(ACID)。这些改进使得SigLIP 2在所有模型规模上均超越了SigLIP,不仅在零样本分类、图像-文本检索等核心能力上表现更强,还在定位任务(如指代表达理解)和密集预测任务(如分割、深度估计)上取得显著提升。此外,SigLIP 2支持多语言理解(109种语言)、原生宽高比和可变分辨率(NaFlex变体),并通过去偏技术改善了公平性。
模型架构:SigLIP 2在架构上与SigLIP保持向后兼容,采用相同的双塔架构设计,使得现有用户可以仅替换模型权重和分词器即可获得性能提升。
-
视觉编码器:标准ViT架构,使用可学习的位置嵌入、pre-LayerNorm、GELU激活和残差连接。SigLIP 2发布了四种模型规模:ViT-B/16(86M参数)、ViT-L/16(303M参数)、ViT-So400m/14(400M参数)和ViT-g/16(~1B参数,搭配So400m-sized文本编码器)。
-
文本编码器:与视觉编码器使用相同的架构(g-sized除外)。采用Gemma多语言分词器,词汇量256k(相比SigLIP的32k大幅增加),文本最大长度扩展至64个token。
-
MAP Head(Multihead Attention Pooling):用于将patch token序列池化为单一表示,与SigLIP保持一致。
-
LocCa解码器(仅训练阶段):标准Transformer解码器,带交叉注意力层,层数为文本编码器的一半,用于图像描述、指代表达预测和定位描述三个任务。解码器仅在预训练期间使用,不包含在发布的模型中。
分阶段训练配方:SigLIP 2采用分阶段训练策略,而非同时应用所有技术,以管理计算和内存开销。
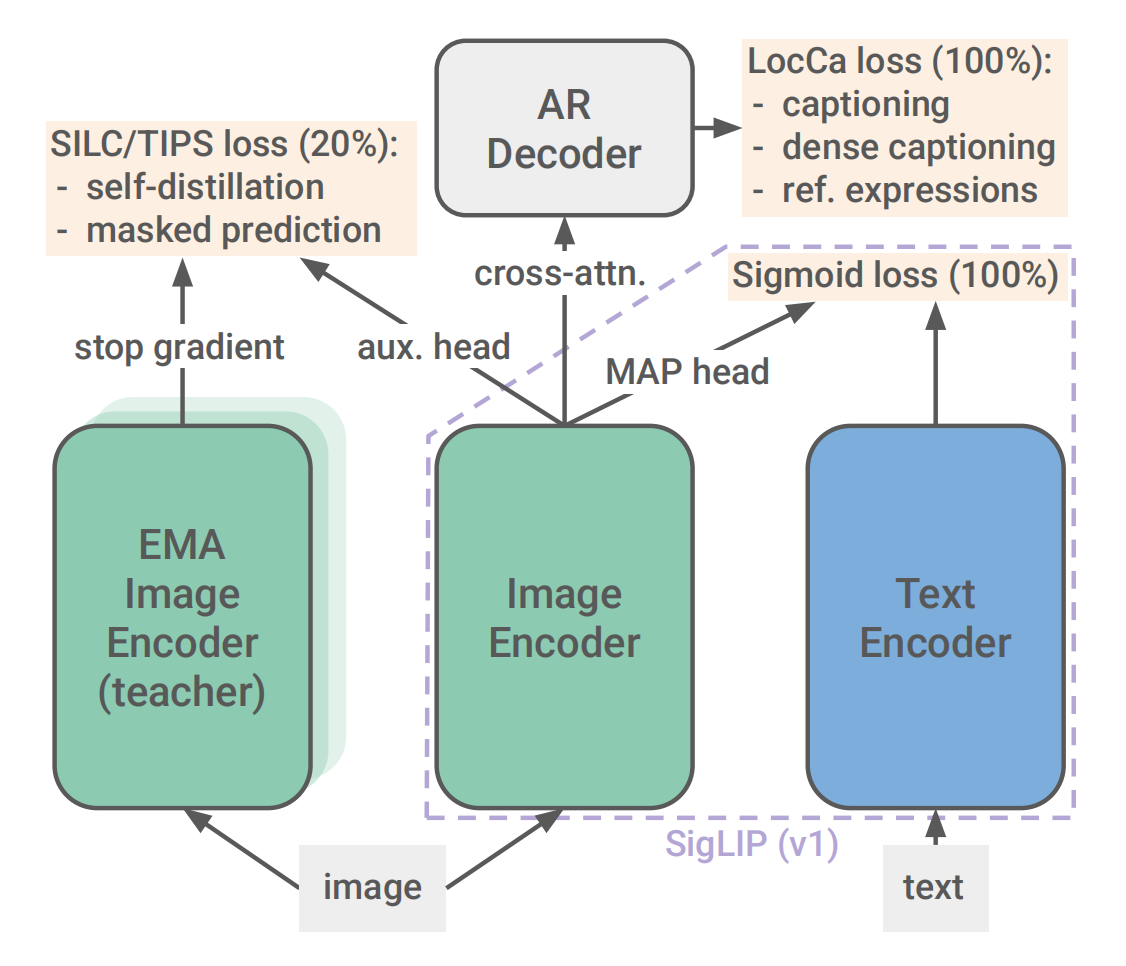
第一阶段:Sigmoid对比损失 + LocCa解码器预训练
此阶段同时训练两个损失:
- Sigmoid对比损失():与原始SigLIP相同的Sigmoid二元分类损失,将图像-文本匹配视为独立的二元分类问题。
- LocCa解码器损失():将标准Transformer解码器附加到未池化的视觉编码器表示上,训练三个任务:
- 图像描述(Image Captioning):生成图像的全局描述
- 自动指代表达预测(Automatic Referring Expression Prediction):预测描述特定图像区域的边界框坐标
- 定位描述(Grounded Captioning):给定边界框坐标,预测区域特定的描述
- 区域-描述对通过从alt-text中提取n-gram并使用OWL-ViT L/14开放词汇检测器自动标注
第二阶段:自蒸馏 + 掩码预测(训练最后20%)
在训练的最后20%阶段,加入自监督损失:
- 自蒸馏损失(,基于SILC):局部到全局一致性学习。学生模型(student)仅看局部视图,教师模型(teacher)看全局视图,教师模型通过EMA(指数移动平均)更新,目标使学生模型的输出与教师模型的输出一致。
- 掩码预测损失(,基于TIPS):学生模型看到50%的可见视觉token(50%被掩码),教师模型看到全部视觉token,目标为预测被掩码的patch特征,使用回归损失。
第三阶段:NaFlex分辨率适应(训练最后10%)
从90%训练完成的checkpoint恢复,切换为保持宽高比的调整大小方式,每批次均匀采样序列长度{128, 256, 576, 784, 1024},将最后10%的学习率调度拉伸3.75倍。此阶段不应用自蒸馏和掩码预测。
小型模型蒸馏阶段(ACID):对于ViT-B/16和ViT-B/32小型模型,使用**ACID(Active Curation as Implicit Distillation)**方法进行额外的4B样本微调,教师模型为SigLIP 2 So400m模型,通过数据选择实现隐式蒸馏。
SigLIP 2的完整训练目标:
其中是Sigmoid对比损失,是LocCa解码器损失,是自蒸馏损失,是掩码预测损失,和是相应的权重系数。
NaFlex变体:原生宽高比与可变分辨率:SigLIP 2引入了NaFlex变体,结合FlexiViT(支持多种预定义序列长度)和NaViT(处理原生宽高比)的思想。调整图像大小使高度和宽度均为patch size的倍数,位置嵌入通过双线性插值动态调整以匹配非方形的patch网格,支持序列长度{128, 256, 576, 784, 1024}。当实际序列长度小于目标时,通过注意力掩码忽略填充token。NaFlex变体对文档理解、OCR等对宽高比敏感的任务特别有益。
训练数据:SigLIP 2在WebLI数据集上训练,包含100亿张图像和120亿个alt-text,覆盖109种语言,数据混合比例为90%英语网页 + 10%非英语网页。使用OWL-ViT L/14生成用于LocCa训练的伪区域标注,并应用了去偏技术减轻对敏感属性的表示偏差。
与SigLIP的对比:
| 方面 | SigLIP (2023) | SigLIP 2 (2025) |
|---|---|---|
| 损失函数 | 仅Sigmoid对比损失 | Sigmoid + LocCa + 自蒸馏 + 掩码预测 |
| 语言支持 | 主要英语 | 109种语言(多语言) |
| 分词器 | SentencePiece (32k vocab) | Gemma Tokenizer (256k vocab) |
| 最大文本长度 | 16 token | 64 token |
| 分辨率支持 | 固定分辨率 | NaFlex可变分辨率 + 原生宽高比 |
| 定位/密集特征 | 较弱 | 显著增强(LocCa + 自监督) |
| 数据策展 | 无 | ACID主动数据策展 |
| 去偏技术 | 无 | Clip the Bias去偏技术 |
| 向后兼容 | - | 与SigLIP完全向后兼容 |
| 训练策略 | 单阶段对比学习 | 三阶段分阶段训练配方 |
技术影响: SigLIP 2作为当前最先进的视觉-语言编码器之一,对领域产生了广泛影响:
- 统一训练配方范式:将对比学习、生成式预训练和自监督学习整合到统一框架中,证明了多目标联合训练的优势,为后续视觉-语言模型的训练提供了新的标准范式。
- 多语言视觉-语言理解的新标准:在109种语言上训练,成为多语言视觉-语言任务的强基准模型,推动了视觉-语言模型的全球化部署。
- 密集预测任务能力提升:通过自蒸馏和掩码预测,显著改善了分割、深度估计、开放词汇检测等密集预测任务的特征质量,拓展了视觉-语言编码器的应用场景。
- 作为视觉骨干的广泛应用:SigLIP 2的视觉编码器被广泛用作多模态大语言模型(MLLM)的视觉骨干,包括Qwen3-VL、PaliGemma 2、LLaVA-MORE等。
- 开源可复现的SOTA:提供了从86M到1B参数的四种规模checkpoint,使不同计算预算的研究者都能受益,推动了视觉-语言研究的民主化。
- 公平性与去偏:通过数据去偏技术减少了表示偏差,在公平性基准上取得显著改进,提升了模型在实际部署中的可信度。
- 后续研究的基础:SigLIP 2的特征被用于分析视觉-语言模型的组合性、位置偏差等基础问题,为领域提供了重要的研究工具。
与历史模型的关系:SigLIP 2是SigLIP的完整继承者和全面升级,核心架构和Sigmoid对比损失保持向后兼容。同时,SigLIP 2整合了多个独立发展技术的精华:LocCa(基于解码器的预训练方法,用于图像描述和定位理解)、SILC(自蒸馏方法,实现局部到全局的特征一致性)、TIPS(掩码预测方法,增强密集特征学习)、NaViT(原生宽高比处理)和FlexiViT(多种序列长度支持)、ACID(通过主动数据策展实现隐式蒸馏)。SigLIP 2证明了将多个互补技术整合到统一框架中可以实现1+1>2的效果,为视觉-语言编码器的未来发展指明了方向。
3.5 ViLT:轻量级图片编码
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision由Nvidia AI Lab发表于ICML 2021
核心贡献:
- 提出了首个完全摒弃卷积神经网络(CNN)和区域级监督的纯Transformer视觉-语言模型架构,通过将图像直接切分为patch并作为token与文本一同输入统一的Transformer编码器进行处理,从而替代了传统多模态模型中计算昂贵、结构复杂的独立目标检测器。
- ViLT提供了原生多模态模型的雏形。
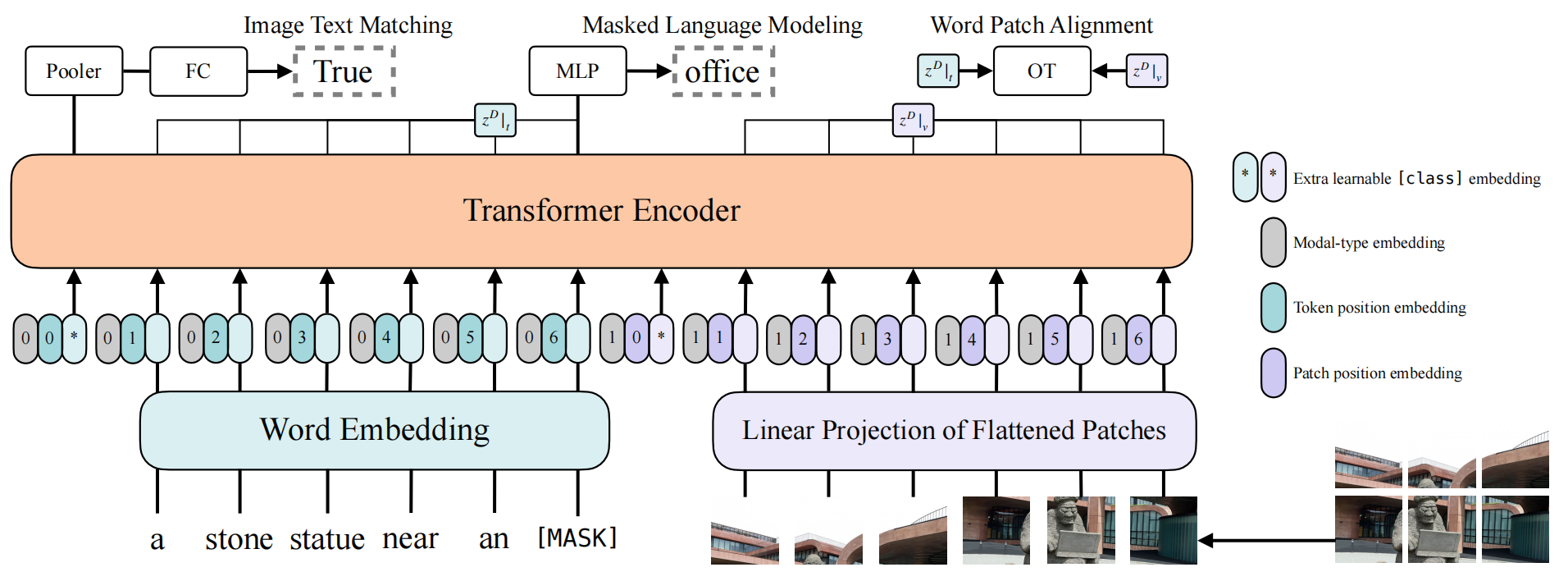
模型架构:
ViLT 采用 Single-Stream 架构(即两种模态在输入层即拼接,共同送入 Transformer),整体可分为三个部分:
-
Text Encoder(文本编码器)。与 BERT 类似,文本侧包含:Word Embedding,Token Position Embedding(可学习的绝对位置编码),Modal-type Embedding(标记该 token 属于文本模态)
-
Image Encoder(图像编码器)。这是 ViLT 与此前 VLP 模型最根本的区别:Patch Projection(输入图像
I ∈ R^(C×H×W)被切分为N = HW/P²个 patch(P=32)),Patch Position Embedding(可学习的位置编码),Modal-type Embedding(标记该 patch 属于图像模态),Extra learnable [class] embedding( ViT 类似,在图像序列前添加一个可学习的 class token)。论文中明确指出,ViLT-B/32 的 patch projection 仅含 2.4M 参数,运行时间可忽略不计。 -
Transformer Encoder(模态交互):基于 ViT-B/32 初始化(而非 BERT),共 D=12 层,Hidden size H=768,MLP 中间层 3072,Attention heads=12。输入拼接:文本嵌入序列与图像嵌入序列拼接为
z⁰ = [t̄ + t^type; v̄ + v^type],共同送入 Transformer:
预训练目标(Pre-training Objectives)。ViLT 使用三个训练目标:ITM (Image Text Matching),MLM (Masked Language Modeling),WPA (Word Patch Alignment)。
与历史模型的关系:受到ViT启发,不使用传统目标检测器(比如Fast R-CNN)来提取图像特征。而是对图像进行切分,然后进行线性投影,将图像转换为image embedding。使用一个ViT-B/32模型来对文本embedding和图像embedding进行融合。
技术影响:
-
ViLT 证明了无需 CNN 和区域监督,仅通过简单的 patch 线性投影,就能在保持极高推理效率的同时,在大多数视觉-语言下游任务上取得具有竞争力的性能。
-
然而,论文作者对 ViLT 的局限性有清醒认识。ViLT-B/32 更多是 “概念验证”(proof of concept),证明"无目标检测器的高效 VLP 是可行的",而非在绝对性能上全面超越深度图像编码器。事实上,ViLT的性能并没有优于UNITER,OSCAR等使用目标检测器的模型。而且ViLT 的训练效率并没有提升。仅仅提升了模型的推理效率。这意味着图文多模态模型还有很大的提升空间。
-
CLIP的局限性在于其双编码器架构缺乏深层次的跨模态交互,不适合需要细粒度视觉推理的任务(如Visual Question Answering,Visual Reasoning, Visual Entailment)。这促使研究者探索如何结合对比学习和融合编码器的优势。
总结:
小结:
从ViLBERT, UNITER, OSCAR, CLIP, ViT, ViLT 这几项工作,可以看出:
- 基于ViT的方案,使用transformer替换目标检测器,可以进行端到端的多模态训练,从而更好的融合多模态数据特征。
- 尽管 CLIP 在图文检索任务上展现出卓越的零样本性能,但CLIP在其他下游视觉-语言任务上并没有卓越的表现。这一结果说明了即便是使用高性能单模态编码器来提取数据特征,如果缺乏深层次的跨模态交互,也不足以学习好需要细粒度视觉推理的任务(如Visual Question Answering,Visual Reasoning, Visual Entailment)。
- ViLT的性能没有优于UNITER,OSCAR等使用目标检测器的多模态模型,说明在没有单独的特征提取器来为不同模态的原始数据提取特征的时候,需要更优的原始数据层面的多模态融合策略。
因此,为了提高模型在多模态融合上的能力,从而更好并且更多的完成下游视觉-语言任务,后续的工作基本都采用了基于transformer的模型架构,研究方向主要集中在(从模型架构,训练方法,训练数据等方面)设计更好的多模态融合方案。
3.6 ALBEF:先对齐后融合(2021年6月)
ALBEF: Align before Fuse: Vision and Language Representation Learning with Momentum Distillation由Salesforce Research于2021年6月提出(NeurIPS 2021发表)[^18]。
**核心贡献:提出了"先对齐再融合"(Align Before Fuse)的核心思想,解决了现有VLP模型中模态对齐不充分的问题。ALBEF还引入了动量蒸馏(Momentum Distillation)**技术,利用动量模型生成伪目标来缓解网络噪声数据的问题。ALBEF在多个下游任务上取得了当时的最优性能。核心贡献在于证明了在融合前进行单模态对齐的重要性,以及动量蒸馏在处理噪声预训练数据中的有效性。
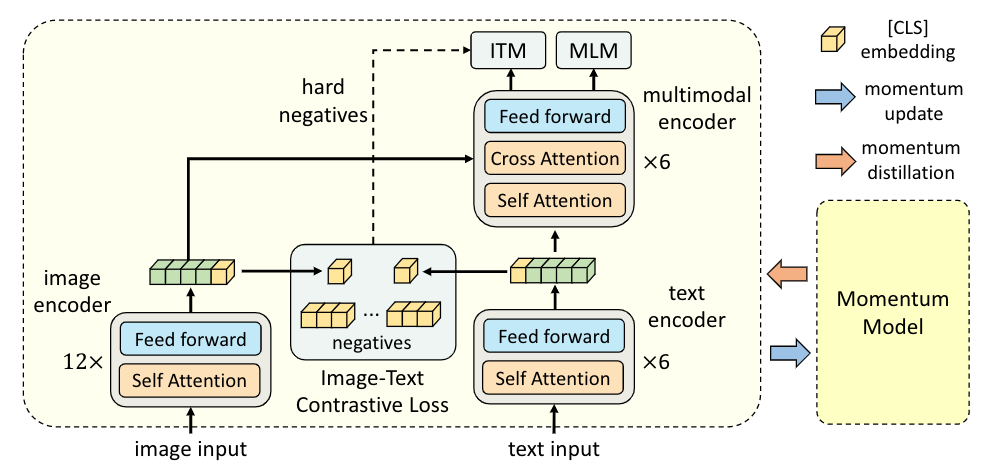
图5:ALBEF模型架构(来自Salesforce论文原图)。ALBEF包含三个组件:图像编码器(ViT)、文本编码器(BERT前6层)和多模态编码器(BERT后6层+交叉注意力)。动量模型通过EMA维护,为训练提供软标签。
ALBEF的架构包含以下关键模块:
-
图像编码器使用ViT-B/16,将图像编码为特征序列。
-
文本编码器使用6层Transformer(BERT-base前6层),将⽂本编码为特征序列。
-
多模态编码器使用6层Transformer(BERT-base后6层),每层包含自注意力层和交叉注意力层。图像和文本首先通过各自的单模态编码器进行编码,然后通过图像-文本对比学习(ITC)损失进行对齐,最后通过多模态编码器进行深层融合,同时施加MLM和ITM损失。
-
动量模型(Momentum Model): 一个缓慢更新的模型副本,用于生成软伪目标(Soft Pseudo-targets)进行动量蒸馏。
预训练目标: ALBEF采用三个预训练目标:
- 图像-文本对比损失(Image-Text Contrastive Loss, ITC): 在单模态编码器输出上计算,对齐图像和文本的表示,为后续的融合编码提供良好的初始化。
- 图像-文本匹配损失(Image-Text Matching Loss, ITM): 在多模态编码器输出上计算,进行二分类判断图像和文本是否匹配。ALBEF创新地使用对比损失中的相似度分布来采样难负样本(Hard Negatives)。
- 掩码语言建模损失(Masked Language Modeling Loss, MLM): 随机掩码文本中的部分单词,利用多模态上下文预测被掩码的单词。
动量蒸馏:ALBEF维护一个动量模型(基于模型参数的指数移动平均),为训练样本生成伪目标作为额外监督。对于被遮蔽的词汇,动量模型生成软标签(概率分布),学生模型同时学习真实标签和软标签。
与历史模型的关系:ALBEF继承了CLIP的对比学习思想和VLP模型的多任务预训练范式。与CLIP相比,ALBEF增加了多模态融合编码器。与OSCAR相比,ALBEF不需要依赖目标检测器。
技术影响: ALBEF的"先对齐再融合"策略成为后续VLP模型的标准设计范式。使用Cross-attention进行多模态数据特征融合,被后续工作广泛采用。ALBEF在图像-文本检索和VQA等任务上取得了当时的最先进结果。
3.7 VLMO:统一的多模态混合专家Transformer
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts由微软发表于NeurIPS 2022
核心贡献: 提出了一种统一的多模态Transformer架构,可以作为双编码器用于检索任务,也可以作为融合编码器用于分类任务,实现了灵活的模型复用。
模型架构设计:
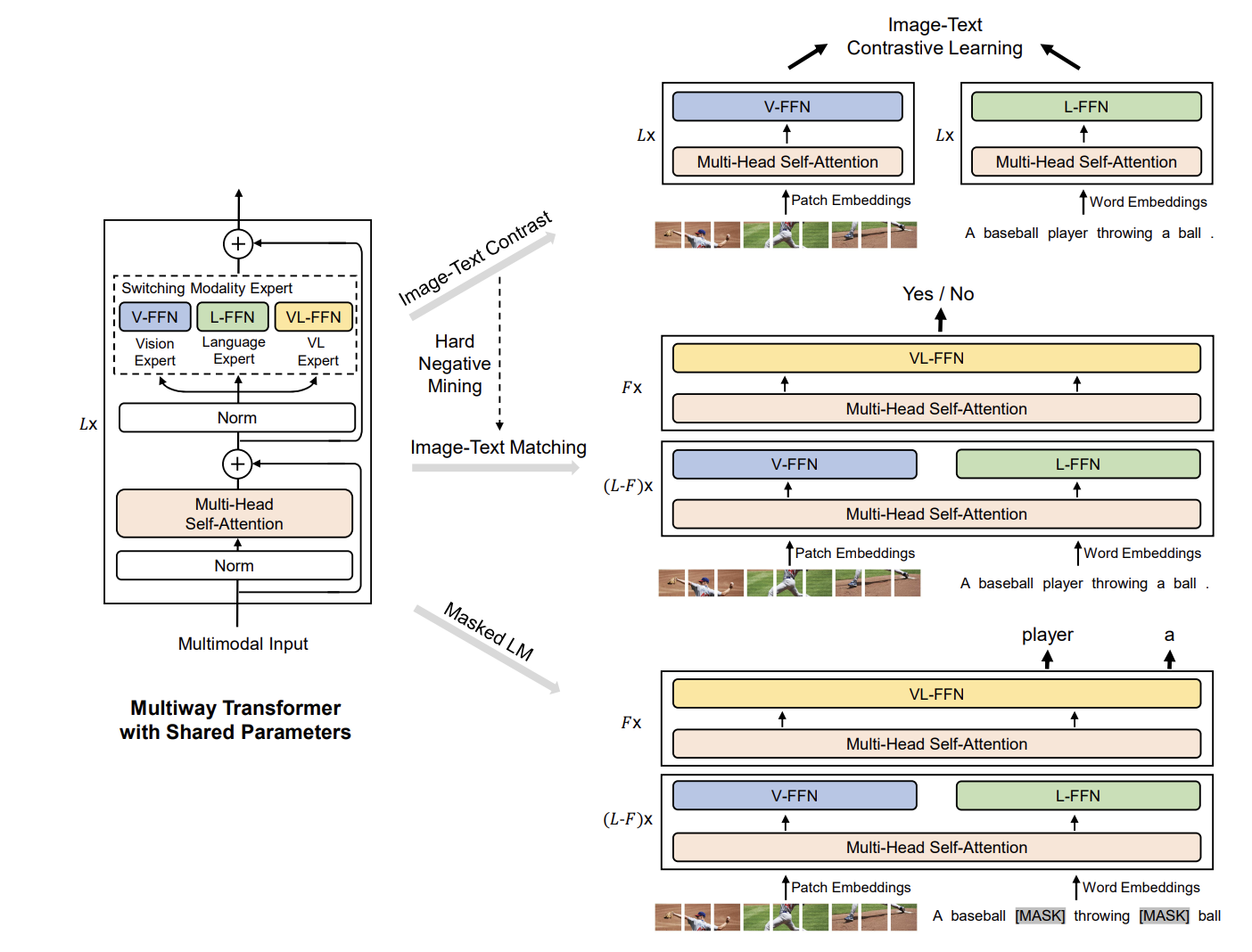
图:VLMO 预训练概述。 引入了多路 Transformer(Multiway Transformer),通过模态专属专家(modality-specific experts)对不同模态的输入进行编码。模型参数在图文对比学习(image-text contrastive learning)、掩码语言建模(masked language modeling)以及图文匹配(image-text matching)这三类预训练任务之间共享。在微调阶段,这种灵活的建模机制能够将 VLMO 用作双编码器(即分别对图像和文本进行编码,适用于检索任务),或用作融合编码器(即联合对图文对进行编码,以促进跨模态间的深度交互)。
VLMO的核心是MOME Transformer(Mixture-of-Modality-Experts Transformer),在每个Transformer块中,自注意力层被所有模态共享(Multi-Head Self-Attention),而前馈网络(FFN)层被替换为模态专家(Modality Experts):
- 视觉专家(Vision Expert, V-FFN): 专门处理视觉特征。
- 语言专家(Language Expert, L-FFN): 专门处理文本特征。
- 多模态专家(Vision-Language Expert, VL-FFN): 处理融合后的多模态特征。
根据输入模态的不同,模型动态选择对应的FFN专家,而自注意力层始终处理所有模态的输入,实现跨模态对齐。
分阶段预训练: VLMO创新地提出了分阶段预训练策略:
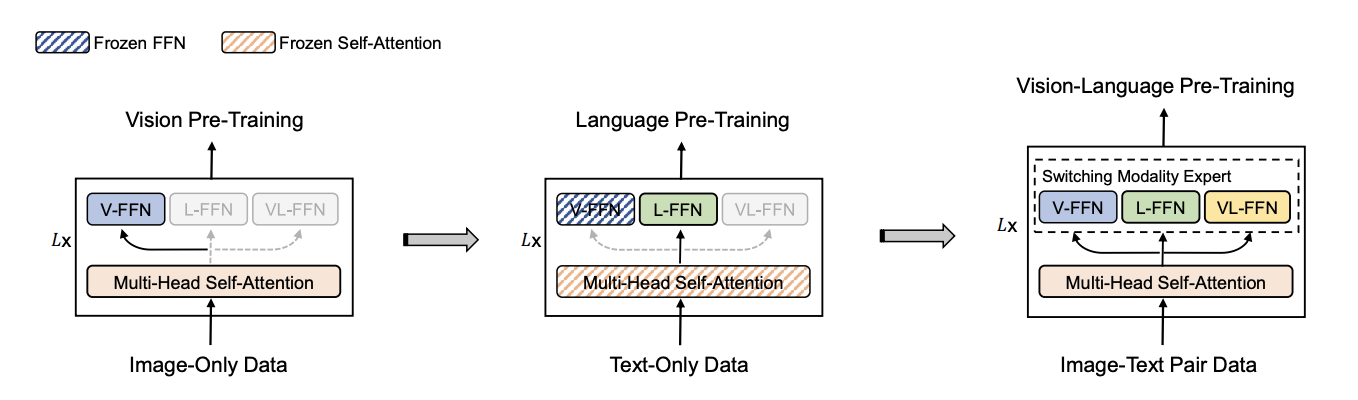
- 第一阶段(Vision Pre-Training): 使用图像数据训练视觉专家和共享的自注意力层(采用BEiT风格的掩码图像建模)。
- 第二阶段(Language Pre-Training): 使用文本数据训练语言专家(采用BERT风格的掩码语言建模),冻结视觉专家和自注意力层。
- 第三阶段(Vision-Language Pre-Training): 使用图像-文本对训练所有模块(采用ITC、ITM和MLM联合目标)。
技术影响: VLMO的MOME Transformer架构被后续的BEiT-3进一步发展,成为多模态Transformer设计的重要参考。分阶段预训练策略有效利用了大规模单模态数据,提升了模型的泛化能力。
3.8 BLIP:引导式语言-图像预训练(2022年1月)
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation由Salesforce Research于2022年1月提出(ICML 2022发表)[^19]。
核心贡献:提出一个统一的视觉-语言理解(Understanding)和生成(Generation)框架。并且提出CapFilt(Captioning and Filtering)机制,通过生成和过滤合成字幕来提升预训练数据的质量。BLIP在七个视觉-语言任务上取得了当时的最优性能,成为首个在理解和生成两类任务上均表现出色的开源视觉-语言模型。
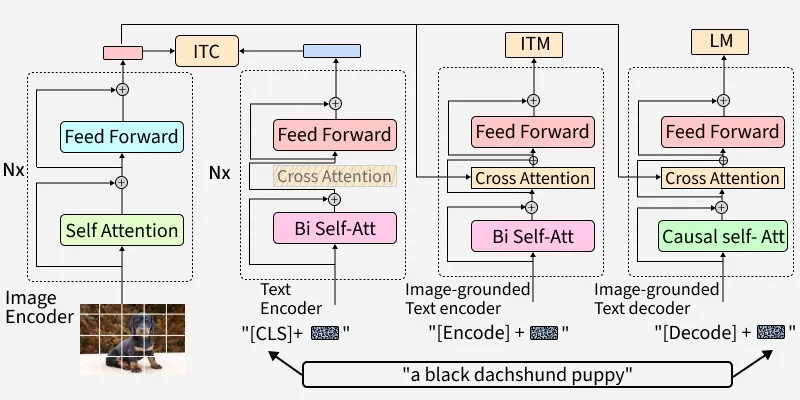
图6:BLIP模型架构(MED多模态混合编码器-解码器)。BLIP包含四个模块:图像编码器(ViT)、单模态文本编码器(BERT,用于ITC)、图像条件文本编码器(交叉注意力,用于ITM)和图像条件文本解码器(因果注意力,用于LM)。
模型架构:BLIP提出了多模态编码器-解码器混合架构(Multimodal mixture of Encoder-Decoder),包含四个功能模块:
- 图像编码器(Image Encoder)和文本编码器(Text Encoder):图像编码器使用ViT,输出[CLS]标记作为全局图像表示。文本编码器使用BERT类似架构。两个编码器的输出用于计算图像-文本对比损失(ITC)。
- 基于图像的文本编码器(Image-grounded Text Encoder): 在文本编码器每个Transformer块的自注意力层和前馈网络之间插入交叉注意力层(Cross-Attention Layer),注入视觉信息。文本输入添加[Encode]令牌,其输出用于图像-文本匹配损失(ITM)。
- 基于图像的文本解码器(Image-grounded Text Decoder): 将文本编码器中的双向自注意力替换为因果(单向)自注意力,用于自回归语言生成。文本输入添加[Decode]令牌,以语言建模损失(Causal LM)进行训练。
三个功能共享相同的Transformer参数,仅在注意力掩码和交叉注意力上有所区别。
预训练目标: BLIP优化3个loss。其中两个是基于理解的loss,一个是基于生成的loss。每个图像-文本对需要在视觉transformer中进行一次前向传播,在文本transformer中进行三次前向传输,计算下面loss:
- 图像-文本对比loss(Image-Text Contrastive Loss):通过图像编码器(Image Encoder)和文本编码器(Text Encoder)的输出计算得到。目的是对齐(拉进)正向图像-文本对在特征空间中的表征。
- 图像-文本匹配loss(Image-Text Matching Loss):通过图像-文本编码器(Image-grounded Text Encoder)计算得到。目的是对齐图像和文本之间细粒度的表征。
- 语言建模loss(Language Modeling Loss):通过图像-文本解码器(Image-grounded Text Dncoder)计算得到。目的是在给定图像的情况下,生成文本描述。
CapFilt数据引导:BLIP的核心创新之一是CapFilt(Captioning and Filtering)。
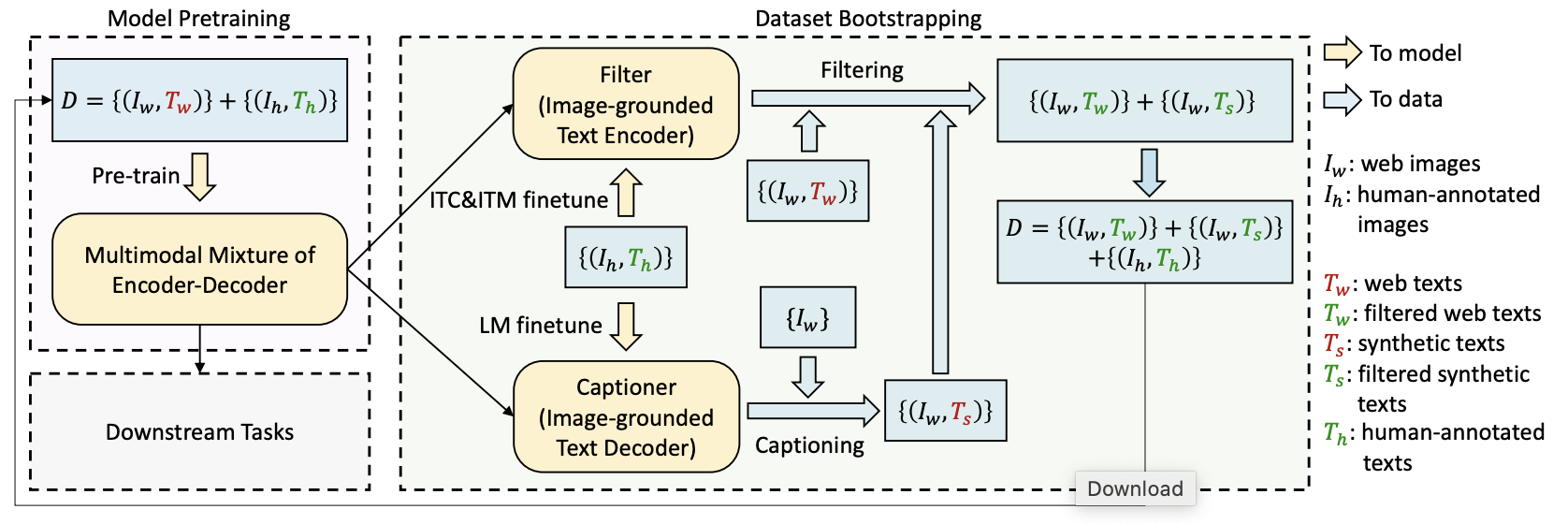
- 过滤器(Filter): 在COCO数据集上微调BLIP的文本编码器(Text Encoder),判断网络Caption和合成Caption是否与图像匹配,剔除噪声数据。
- Caption生成器(Captioner): 在COCO数据集上微调BLIP的文本解码器 (Text Decoder),为网络图像生成合成Caption。
- 数据合成: 将过滤后的合成Caption与人工标注Caption合并,构成更高质量的预训练数据集。
与历史模型的关系:BLIP继承了ALBEF的对比学习思想和VLMO的混合专家预训练范式,并在此基础上引入了基于解码器的语言建模能力(Causal LM)。BLIP的CapFilt方法改进了ALBEF的动量蒸馏。BLIP为后续的BLIP-2奠定了基础。
技术影响: BLIP的MED架构统一了理解和生成任务,CapFilt机制有效提升了数据质量。BLIP在广泛的下游任务上取得了当时的最先进结果,包括图像-文本检索、图像描述生成、VQA和视觉推理等。BLIP的成功催生了BLIP-2和多模态LLM时代的系列后续工作。
3.9 Flamingo:少样本视觉语言模型(2022年4月)
Flamingo: A Visual Language Model for Few-Shot Learning由DeepMind于2022年4月提出(NeurIPS 2022发表)
核心贡献:在16个多模态基准测试中,仅用4个示例就超过了在数千倍数据上微调的模型。证明了在冻结语言模型中插入轻量门控交叉注意力层即可实现强大的少样本视觉理解。
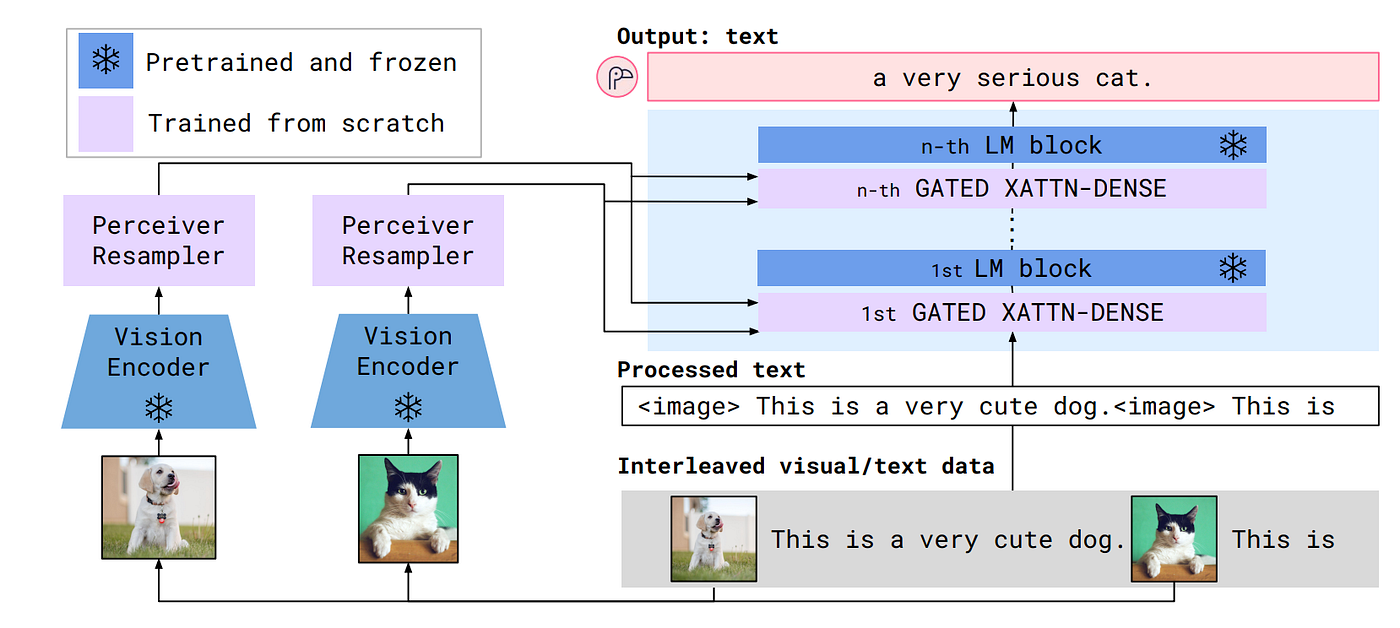
图7:Flamingo完整架构(来自DeepMind论文原图)。左侧:冻结的视觉编码器(NFNet)和Perceiver Resampler处理输入图像。右侧:在冻结的Chinchilla语言模型块之间插入新训练的GATED XATTN-DENSE层。
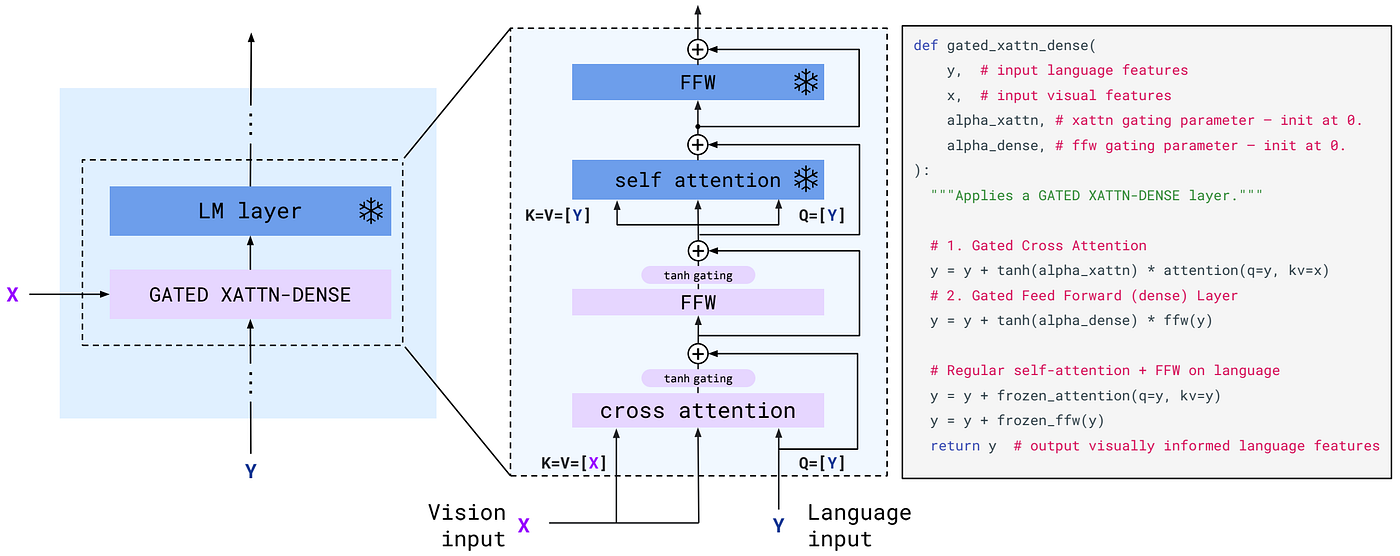
图8:Flamingo的GATED XATTN-DENSE层详细结构。包含交叉注意力层(Q来自语言表示,K/V来自视觉token)和前馈网络(FFW),每个新组件通过tanh(alpha)门控机制与残差连接相加。
模型架构:Flamingo包含四个关键组件。
(1) 视觉编码器:使用预训练且冻结的NFNet F6模型。
(2) Perceiver Resampler:将可变数量的图像特征通过可学习的64个latent query向量进行交叉注意力计算,输出固定64个视觉token,大幅降低后续计算复杂度。
(3) GATED XATTN-DENSE层:在冻结的Chinchilla语言模型块之间插入新训练的交叉注意力层。引入tanh门控机制:新层输出乘以tanh(alpha)(alpha初始化为0),通过残差连接添加。tanh(0)=0确保初始化时不破坏语言模型能力。
(4) 多视觉输入支持:通过注意力掩码机制支持交错的图文序列输入。
训练数据:M3W(1.85亿交错图文)、ALIGN+LTIP(3.12亿图像-文本对)、VTP(2700万视频-文本对)。三个版本:Flamingo-3B、Flamingo-9B、Flamingo-80B。
与历史模型的关系:Flamingo的架构直接影响了BLIP-2(Q-Former桥接)、LLaVA(线性投影连接)。Perceiver Resampler和门控交叉注意力设计被广泛采用。
3.10 CoCa:对比式Caption生成器(2022年5月)
CoCa: Contrastive Captioners are Image-Text Foundation Models由Google Research于2022年5月提出(TMLR 2022发表)
**核心贡献:将对比学习(Contrastive Learning)和生成式captioning(Generative Captioning)**统一到一个模型中,兼具两者的优势。
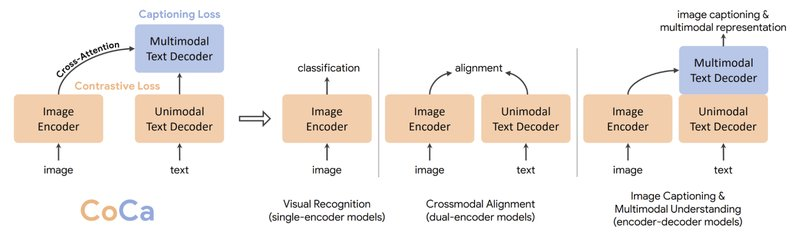
图9:CoCa模型架构(来自Google Research原图)。CoCa结合了三种范式的优势:单编码器(用于视觉识别)、双编码器(用于跨模态对齐)和编码器-解码器(用于图像描述和多模态理解)。
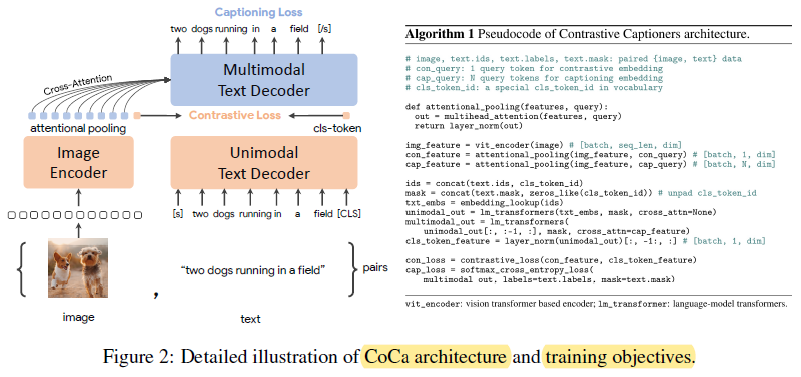
图10:CoCa详细架构和训练目标。图像通过ViT编码器编码,经过注意力池化后与文本表示计算对比损失。多模态文本解码器通过交叉注意力关注图像特征。
CoCa的架构包含三个核心组件:
- 图像编码器(Image Encoder): 采用Vision Transformer,将图像编码为特征序列。
- 单模态文本解码器(Unimodal Text Decoder): 解码器的前半部分不包含交叉注意力,仅处理文本序列,生成文本的[CLS]表示用于对比学习。
- 多模态文本解码器(Multimodal Text Decoder): 解码器的后半部分包含交叉注意力层,可以关注图像特征,用于生成caption。
训练目标:
- 对比损失(Contrastive Loss): 基于Image Encoder输出的图像特征和Unimodal Text Decoder输出的文本特征,计算对比学习loss,类似于CLIP。
- 图片描述损失(Captioning Loss): 使用Multimodal Text Decoder的输出进行自回归Captioning loss。Multimodal Text Decoder 在交叉注意力层如何了来自Image Encoder的图像特征和来自Unimodal Text Decoder的文本特征。
核心贡献:CoCa在图像描述生成、VQA、零样本分类等任务上取得优异性能。证明了对比学习和生成学习可以协同工作。
与历史模型的关系:
CoCa(Contrastive Captioner)在架构和训练方法上继承并融合了多条技术路线的成果,同时通过其独特的解耦解码器设计实现了创新突破。
与ALBEF的关系(架构继承与关键改进):
CoCa基本采用了ALBEF的双塔编码器+融合编码器的整体架构框架。与ALBEF不同的是,CoCa将ALBEF中的融合编码器(fusion encoder)替换为多模态文本解码器(multimodal text decoder)。这一改动是本质性的:ALBEF的融合编码器仅能输出编码表示,无法直接生成文本;而CoCa的解码器具备自回归生成能力,可以同时支持对比学习和生成式训练。具体而言,CoCa保留了ALBEF的单模态图像编码器和单模态文本编码器用于对比学习(image-text contrastive loss),但去掉了融合编码器部分,改用带交叉注意力的Transformer解码器来生成图像标题。
与CLIP的关系(对比学习的继承):
CoCa直接继承了CLIP开创的图像-文本对比学习范式。CoCa使用与CLIP相同的单模态编码器结构(不共享参数的双塔架构),通过对比损失学习图像和文本在统一嵌入空间中的对齐关系。CLIP证明对比学习可以学习强大的零样本迁移表示,CoCa在此基础上进一步证明对比学习与生成式训练可以协同工作——对比学习负责学习粗粒度的模态对齐,生成式训练负责学习细粒度的语义细节。
与SimVLM/GIT的关系(生成式方法的融合):
CoCa与SimVLM和GIT同为生成式VLP模型,都采用了encoder-decoder架构进行训练。SimVLM使用PrefixLM在大规模数据上进行生成式预训练,GIT则使用图像编码器+文本解码器的极简架构。CoCa的独特之处在于同时结合了对比学习和生成式训练(因此得名"Contrastive Captioner"),而SimVLM和GIT仅使用生成式目标。这种"双目标训练"使CoCa在保持生成能力的同时,获得了强大的零样本分类和检索能力——这是纯生成式模型(SimVLM/GIT)所不具备的。
CoCa的独特创新(解耦解码器设计):
CoCa最核心的创新是其**解耦解码器(Decoupled Decoder)**设计:
- 解码器的前半部分(浅层)同时参与对比学习和生成式训练
- 解码器的后半部分(深层)仅参与生成式训练(带因果掩码的自回归语言建模)
- 这种设计使得对比学习和生成学习的梯度不会相互干扰,同时允许解码器的前半部分作为"轻量级融合编码器"输出高质量的图文联合表示
- 解耦设计巧妙地解决了"对比学习需要双向注意力,生成学习需要因果注意力"的矛盾
技术总结:CoCa可以看作是ALBEF的架构 + CLIP的对比学习 + SimVLM/GIT的生成能力的融合体,通过解耦解码器这一创新设计实现了三者的有机统一。
技术影响: CoCa的统一设计使其可以执行多种任务:作为单编码器进行视觉分类,作为双编码器进行跨模态检索,作为编码器-解码器进行图像字幕生成和VQA。CoCa在ImageNet上取得了86.3%的零样本top-1准确率(当时最先进),微调后达到91.0%。
3.11 BEiT-3:通用多模态基础模型(2022年8月)
BEiT-3: Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks由微软于2022年8月提出(CVPR 2022发表)。
核心贡献: 提出了一个通用的多模态基础模型,采用Multiway Transformer架构和统一的**掩码数据建模(Masked Data Modeling)**预训练任务,在视觉和视觉-语言任务上均取得了最先进的结果。
架构设计:
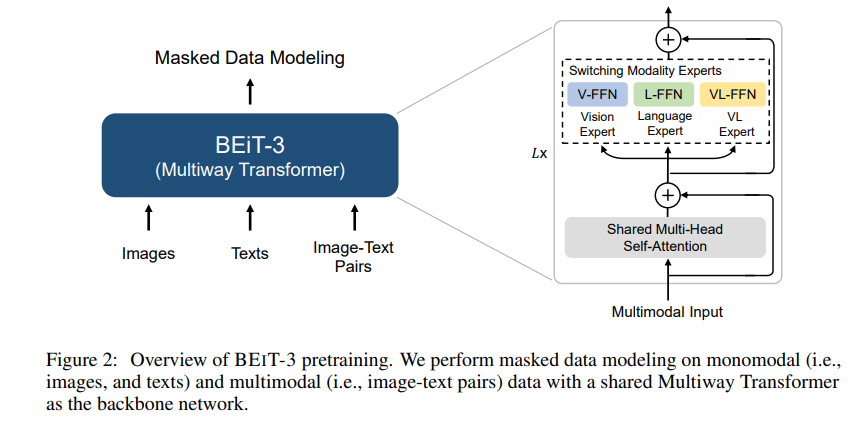
图11:BEiT-3模型架构(来自Microsoft论文原图)。BEiT-3使用多路Transformer在图像、文本和图像-文本对上进行统一的掩码数据建模预训练。
BEiT-3的核心是Multiway Transformer,这是对VLMO的MOME Transformer的进一步发展:
- 共享的自注意力层: 所有模态共享自注意力权重,实现跨模态信息交互。
- 模态专家前馈网络: 每个Transformer块包含多个并行的FFN专家,包含 视觉专家(V-FFN) 处理图像、语言专家(L-FFN) 处理文本、融合专家(VL-FFN) 处理图像-文本对,根据输入模态,通过路由机制选择对应的专家。
统一预训练目标:使用单一的掩码数据建模(Masked Data Modeling) 目标。图像使用BEiT v2的语义视觉token转换为离散token序列。文本使用BERT的MLM目标。图像-文本对同时掩码视觉和文本token。
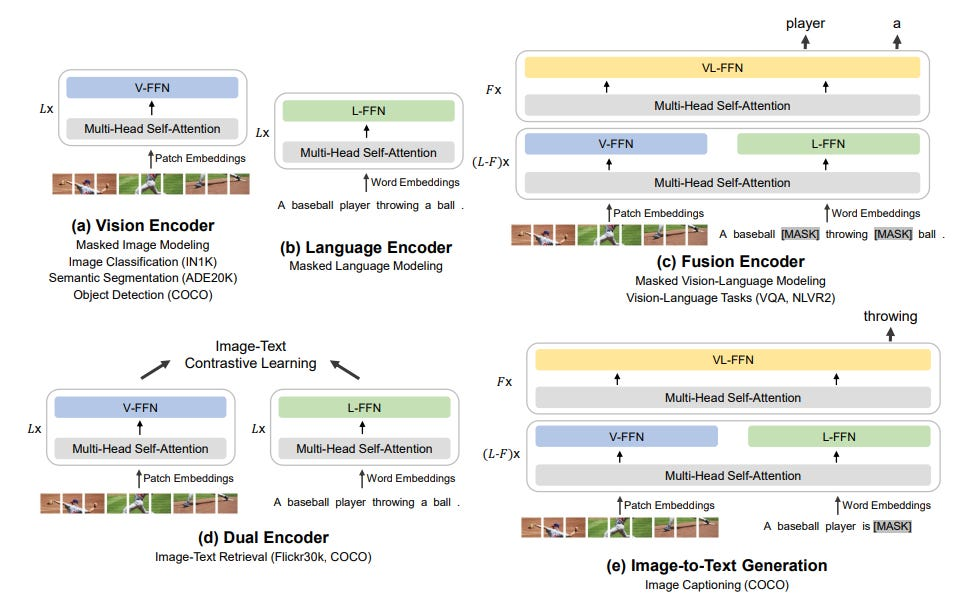
图12:BEiT-3多路Transformer的详细架构。共享的多头自注意力层处理所有模态输入,通过Switching Modality Experts选择V-FFN、L-FFN或VL-FFN进行处理。
BEiT-3可以灵活适应不同的下游任务:
- 视觉编码器: 仅使用V-FFN专家,用于图像分类、目标检测等。
- 语言编码器: 仅使用L-FFN专家,用于文本理解。
- 融合编码器: 使用VL-FFN专家,用于VQA、视觉推理等。
- 双编码器: 分别使用V-FFN和L-FFN,用于图像-文本检索。
- 序列到序列: 使用所有专家,用于图像字幕生成。
与历史模型的关系:"Image as a Foreign Language"思想受ViT和BEiT启发。多路Transformer借鉴了VLMO的设计。
技术影响: BEiT-3展现了统一多模态Transformer架构的强大潜力,其"将所有内容视为外语"的理念深刻影响了后续多模态大模型的设计。BEiT-3形成的原生多模态模型的雏形,为后续原生多模态模型(比如,Chameleon)的研究奠定了基础。
3.12 PaLI:Google的多语言视觉-语言模型系列
PaLI(Pathways Language and Image)是Google Research提出的一系列大规模多语言视觉-语言模型。该系列从2022年到2023年经历了三代演进——PaLI(17B)、PaLI-X(55B)和PaLI-3(5B),探索了视觉-语言模型在不同缩放策略下的性能表现。PaLI系列的核心设计哲学是联合缩放(joint scaling):视觉和语言两个模态的组件需要同步、均衡地放大,而非单一方向的极致扩展。
3.12.1 PaLI (Pathways Language and Image model)
PaLI: A Jointly-Scaled Multilingual Language-Image Model由Google Research的Xi Chen等人于2022年9月提出(ICLR 2023发表,Kigali, Rwanda)。
核心贡献:PaLI是PaLI系列的开篇之作,其核心贡献在于:(1)提出 “联合缩放”(jointly-scaled)范式,系统证明同时放大视觉和语言组件对视觉-语言任务性能提升至关重要;(2)构建了WebLI大规模多语言数据集,将视觉-语言预训练从英语为主扩展到109种语言;(3)采用模块化设计,复用高质量预训练的单模态骨干(mT5和ViT-e),引入8种预训练任务的多任务混合策略,展示了这种设计的高效性和可扩展性。
模型架构:
PaLI采用编码器-解码器Transformer架构,整体设计简洁且高度模块化,由两个核心组件构成:
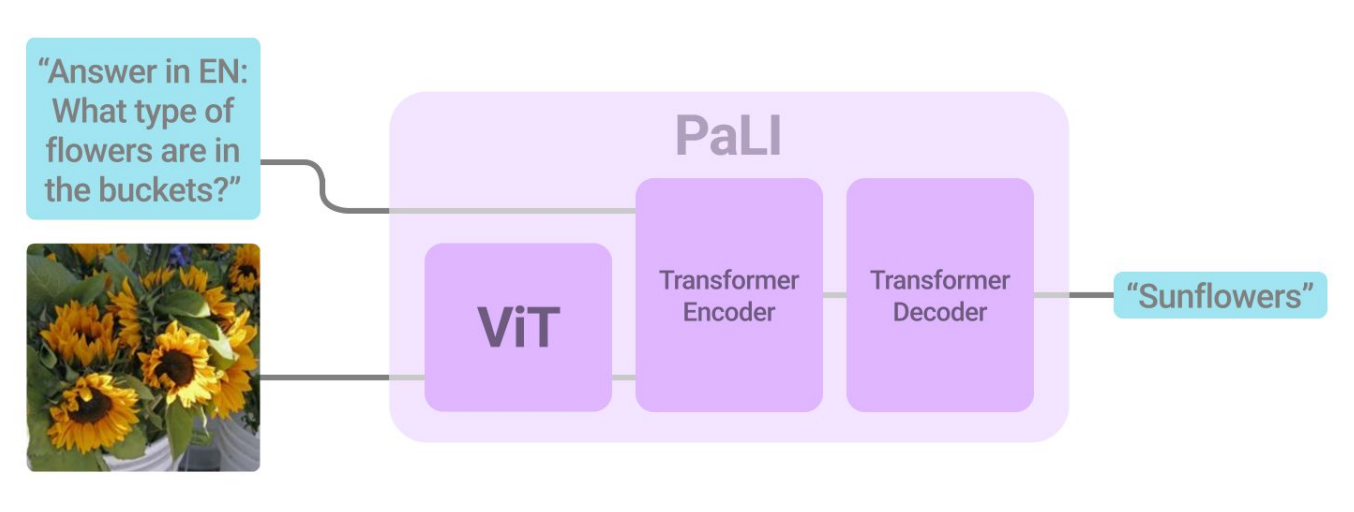
图:PaLI模型架构示意图。图像通过ViT-e视觉编码器编码为patch-level embeddings,与文本token embeddings拼接后送入mT5编码器-解码器进行自回归文本生成。
(1)文本编码器-解码器(语言组件):基于mT5(multilingual T5)架构。PaLI使用mT5-XXL(130亿参数)作为主要版本,另有mT5-Large(10亿参数)的轻量版本。mT5-XXL是原始Transformer编码器-解码器架构的多语言扩展,从预训练的mT5检查点初始化,保留了强大的多语言理解和生成能力。
(2)视觉编码器(视觉组件):基于ViT-e(Vision Transformer — e表示"enormous"),拥有40亿参数,是当时最大的纯ViT架构。ViT-e的架构与18亿参数的ViT-G相同,但进一步缩放至4B规模。它使用与ViT-G相同的训练方法,但进行了两次学习率冷却(一次带inception crop增强,一次不带),并将两组权重平均(即模型汤/model soup技术)。ViT-e从预训练的ViT-G检查点进一步训练得到。
模型配置:
| 模型版本 | 语言组件 | 视觉组件 | 总参数量 |
|---|---|---|---|
| PaLI-3B | mT5-Large (1B) | ViT-e (4B) | ~3B |
| PaLI-15B | mT5-XXL (13B) | ViT-e (4B) | ~15B |
| PaLI-17B | mT5-XXL (13B) | ViT-e (4B) | ~17B |
输入输出流程:输入为图像和文本(问题/提示/前缀)。ViT将图像编码为图像嵌入(patch-level embeddings),图像嵌入与文本token嵌入拼接后输入mT5编码器-解码器,最终自回归生成文本输出(caption/答案等)。所有任务统一表示为文本到文本的生成问题。
训练方法:
PaLI使用8种预训练任务的多任务混合策略:
- Span Corruption(纯文本数据)— 保持语言理解能力
- Split-Captioning(WebLI alt-text)— 将caption拆分为前缀和后缀进行预测
- Multilingual Captioning(CC3M-35L,35种语言)
- Visual Question Answering(VQ2A-CC3M-35L)
- Object-Aware VQA(Open Images, Visual Genome, Object365)
- OCR-related tasks(WebLI OCR注释)
- Object Detection(基于Pix2Seq方法,将检测任务转化为文本生成)
- Pure Language Understanding Tasks — 防止mT5多语言能力的灾难性遗忘
核心数据集——WebLI:PaLI的最大数据贡献之一是构建了WebLI数据集。该数据集从公开网络抓取,包含100亿图像和120亿alt-text,覆盖109种语言。使用GCP Vision API提取OCR注释,产生290亿image-OCR对。通过跨模态相似度评分筛选,保留top 10%(约10亿高质量图像-文本对)用于训练。此外还对68个常见视觉/视觉-语言数据集进行近重复检测和消除(仅移除0.36%),确保评估的公平性。
训练策略:使用Google的Pathways系统在TPU v4集群上训练,软件栈为JAX、Flaxformer和T5X。视觉编码器和语言编码器分别从各自的预训练检查点初始化。关键设计是在训练时同时包含纯语言理解任务,有效避免了多语言能力的灾难性遗忘。
与历史模型的关系:
PaLI的技术继承主要来源于四个方向:mT5(Xue et al., 2021)提供多语言编码器-解码器基础架构;ViT/ViT-G(Dosovitskiy et al., 2021; Zhai et al., 2022a)提供视觉编码器基础架构;T5(Raffel et al., 2020)提供整体编码器-解码器架构设计;Pix2Seq(Chen et al., 2022)提供对象检测任务的序列化方法。
与同期模型的区别:相比于Flamingo(Alayrac et al., 2022)冻结视觉编码器并侧重少样本学习,PaLI强调两个组件的协同训练和联合缩放。相比于GIT(Wang et al., 2022)侧重缩放视觉组件(4.8B ViT + 300M语言解码器),PaLI同时缩放两个组件,开创了"jointly-scaled"范式。
技术影响:PaLI确立了视觉-语言模型中视觉和语言组件需要同步缩放的联合缩放范式,被后续PaLI-X、PaLI-3等模型继承。WebLI数据集开创了大规模多语言视觉-语言预训练数据的构建方法,后续被SigLIP、WebLI-100B等工作扩展。PaLI的模块化设计展示了复用高质量单模态预训练骨干的有效性,成为后续VLM的标准做法。在100+种语言的跨模态检索、多语言图像描述、VQA等任务上取得了当时的SOTA结果。
PaLI后续迭代包括PaLI-X和PaLI-3
- PaLI-X是PaLI的大规模扩展版本,核心贡献包括:(1)将视觉-语言模型缩放到55B参数(ViT-22B + UL2-32B),系统证明性能在该规模下仍未饱和;(2)引入多目标混合训练(prefix completion + masked-token prediction),显著改善了微调与少样本学习之间的帕累托前沿;(3)通过OCR预训练增强视觉编码器的文本理解能力;(4)展示了复杂计数、多语言目标检测等涌现能力。
- PaLI-3是PaLI系列的第三代模型,以一种"返璞归真"的姿态证明:规模并非唯一路径。其核心贡献包括:(1)证明仅5亿参数的VLM可以在多个基准上与比它大10倍的模型竞争或超越;(2)系统比较了分类预训练ViT与对比预训练(SigLIP)ViT,发现对比预训练的视觉编码器在视觉-语言任务(尤其是文本理解和定位任务)上显著更优;(3)将SigLIP图像编码器缩放至20亿参数,在多语言跨模态检索上达到新SOTA;(4)提出了改进的三阶段训练策略和高分辨率训练方法。
PaLI系列三代模型的演进脉络:
| 维度 | PaLI (2022) | PaLI-X (2023) | PaLI-3 (2023) |
|---|---|---|---|
| 视觉组件 | ViT-e (4B) | ViT-22B (22B) | SigLIP ViT-G/14 (2B) |
| 视觉预训练方式 | JFT分类预训练 | JFT分类+OCR增强 | SigLIP对比预训练 |
| 语言组件 | mT5-XXL (13B) | UL2 (32B) | UL2-3B (3B) |
| 总参数量 | ~17B | ~55B | ~5B |
| 预训练任务数 | 8种 | 13种 | 继承+优化 |
| 核心创新 | 联合缩放、WebLI | 规模化验证、OCR增强 | 对比预训练、高效训练 |
| 设计哲学 | 均衡放大双组件 | 极致规模化 | 规模精简、方法优化 |
PaLI系列三代模型共同构成了一部视觉-语言模型发展史的微缩画卷:PaLI确立了联合缩放的设计原则和模块化架构范式;PaLI-X验证了规模化的极限和OCR增强的有效性;PaLI-3则以精炼之姿证明,训练方法的创新可以弥补甚至超越规模的差距。这一思想直接催生了PaliGemma等开源模型,深刻影响了后续视觉-语言模型的设计方向。
4. 以LLM为核心的多模态架构(2023—2025)
2023年,随着GPT-4、LLaMA等大型语言模型(LLM)的爆发式发展,Image-to-Text领域进入了一个全新的时代。核心范式转变为:使用预训练的视觉编码器提取图像特征,通过轻量的适配模块将视觉特征对齐到LLM的输入空间,利用LLM强大的语言生成和推理能力完成各种视觉-语言任务。
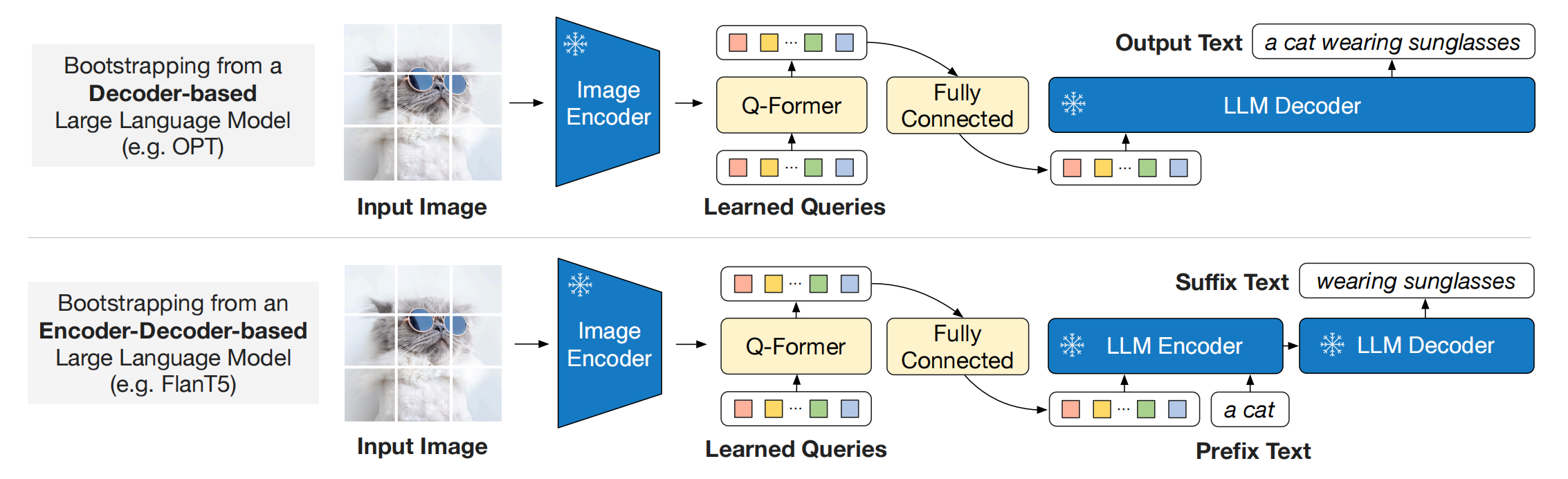
4.1 BLIP-2:桥接冻结的视觉编码器与大语言模型(2023年1月)
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models由Salesforce Research于2023年1月提出(ICML 2023发表)[^23]。
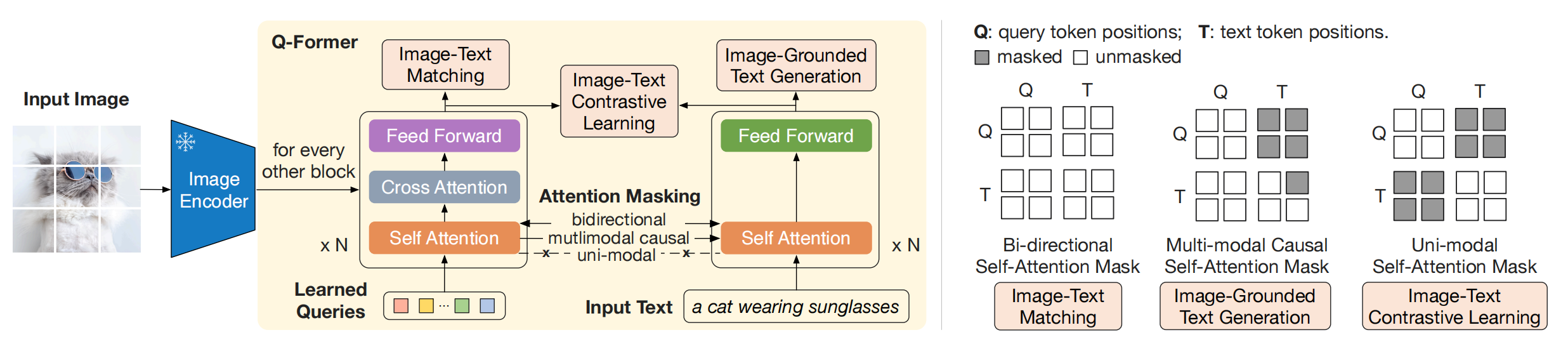
核心贡献: 提出了一种高效的方法,将冻结的预训练视觉编码器和冻结的LLM对接,仅需训练一个轻量的Q-Former模块(188M参数),大幅降低了多模态训练的计算成本。
BLIP-2的架构包含三个模块:
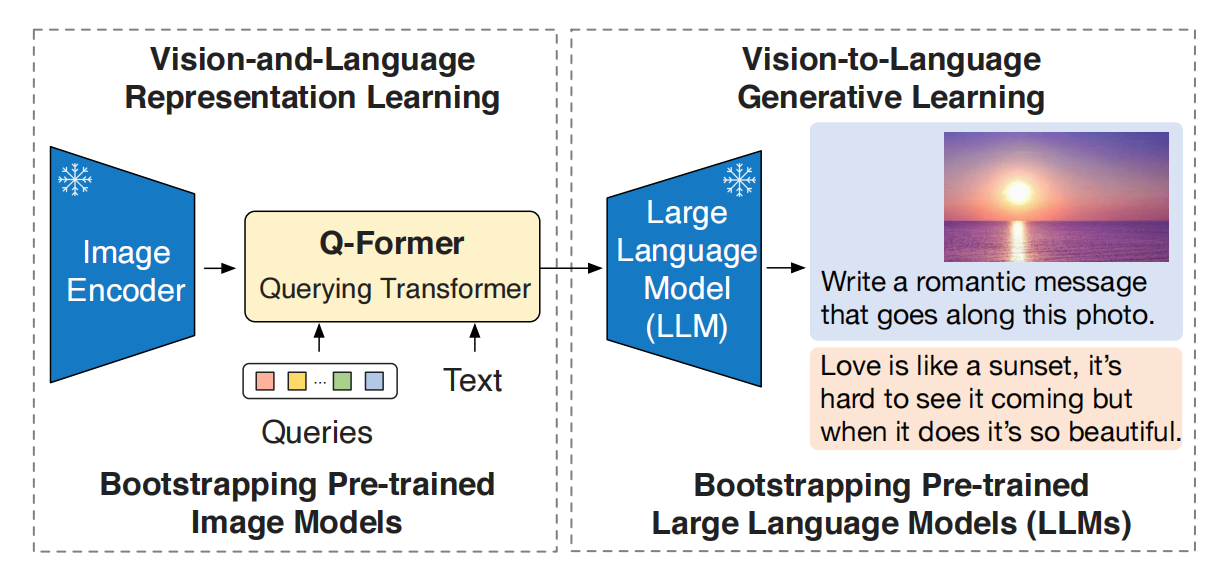
-
冻结的视觉编码器(Frozen Image Encoder): 采用预训练CLIP的ViT-L/14或EVA-CLIP的ViT-g/14,参数完全冻结。
-
冻结的LLM(Frozen LLM): 采用OPT(decoder-only)或FlanT5(encoder-decoder),参数完全冻结。
-
Q-Former(Querying Transformer): 一个轻量的Transformer模块(约188M参数),用于桥接一个冻结的视觉编码器和一个冻结的LLM。他包含可学习的查询嵌入(Learned Query Embeddings)和交叉注意力层。具体包括两个子模块,他们共享自注意力层:
- 图像Transformer, 他与冻结的图像编码器进行交互,进行视觉特征提取。
- 文本Transformer, 既可以作为文本编辑器,又可以作为文本解码器。
两阶段训练:
-
阶段一:视觉-语言表示学习。 训练Q-Former中的learnable query embeddings和cross attention,旨在从视觉编码器提取与文本对齐的视觉表征。注意:Learnable Query Embedding 既不是纯粹的文本语义,也不是纯粹的图像语义,而是"面向文本任务的视觉语义压缩表示"(Task-oriented Visual Semantics)——可以理解为 LLM 能读懂的"视觉伪词元"(Visual Pseudo-Tokens)。通过优化三个loss来达到训练Q-Former的目的:
- 图像-文本对比学习(Image-Text Contrastive Learning, ITC) 旨在学习对齐图像表征与文本表征,使得二者的互信息最大化。它通过将正样本对的图像-文本相似度与负样本对的相似度进行对比来实现这一目标。
- 图像-文本匹配(Image-Text Matching, ITM) 旨在学习图像表征与文本表征之间的细粒度对齐。这是一个二分类任务,模型需要预测一个图像-文本对是正样本(匹配)还是负样本(不匹配)。
- 基于图像的文本生成(Image-grounded Text Generation, ITG)损失 训练 Q-Former 以输入图像为条件生成文本。
-
阶段二:视觉到语言生成学习。 将Q-Former的输出通过全连接层投影到LLM的输入空间,训练Q-Former使其输出的视觉表征能够被LLM理解,用于生成文本。支持两类LLM
- 基于解码器的 LLM,采用语言建模损失(language modelling loss)进行预训练,冻结的 LLM 负责基于 Q-Former 输出的视觉表示来生成文本。
- 基于编码器-解码器的 LLM,采用前缀语言建模损失(prefix language modelling loss)进行预训练,将文本切分为两部分:前缀文本(prefix text)与视觉表示拼接后,作为 LLM 编码器的输入;后缀文本(suffix text)作为LLM解码器的生成目标。
技术影响: BLIP-2证明了通过轻量适配器可以高效地将视觉能力注入LLM,开创了"冻结LLM+可学习桥接"的多模态大模型范式。这一范式被后续的LLaVA、InstructBLIP等工作广泛采用和发展。
与历史模型的关系:继承BLIP的预训练目标,引入全新Q-Former架构。与Flamingo相比,Q-Former更加轻量且与LLM接口更直接。
参考:BLIP-2解读
4.2 LLaVA:大型语言与视觉助手(2023年4月)
LLaVA: Large Language and Vision Assistant由威斯康星大学麦迪逊分校和微软研究院于2023年4月联合发表于NeurIPS 2023。
核心贡献:
- 提出了视觉指令微调这一训练范式。与此前 BLIP-2、Flamingo 等依赖复杂预训练或大量配对数据的工作不同,LLaVA 证明了仅需在已有的大规模语言模型(LLM)和视觉编码器之间插入一个轻量级连接层,通过两阶段训练即可实现高质量的多模态对话能力。
- 系统性地利用纯语言GPT-4模型来生成大规模多模态指令跟随数据。
LLaVa模型架构图:
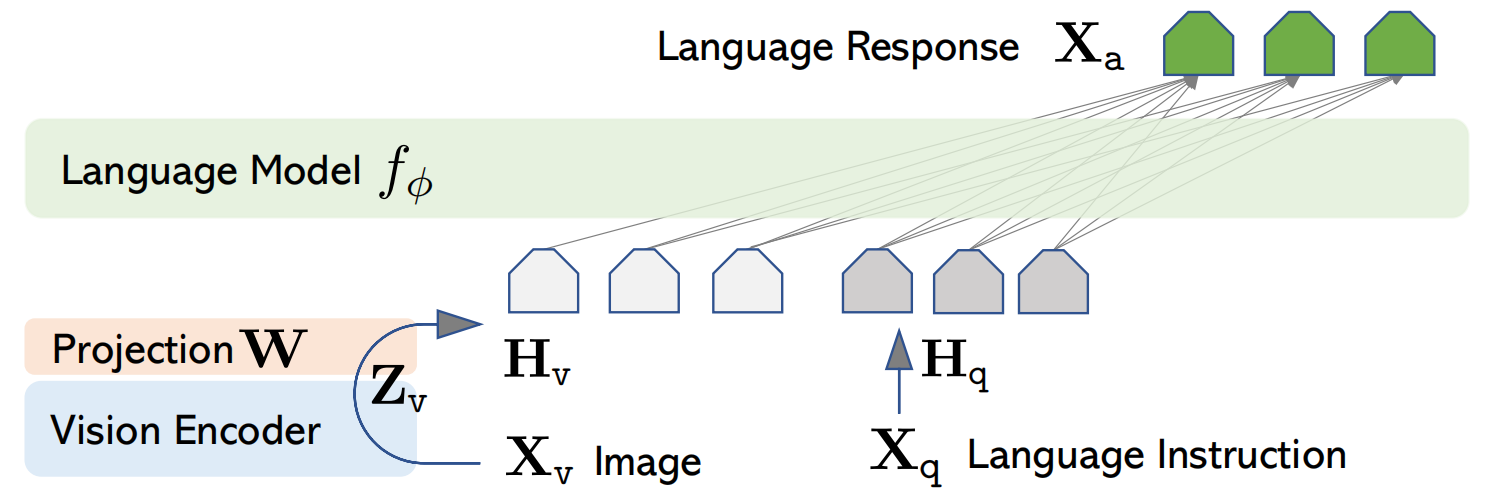
图15:LLaVA模型架构(来自原始论文)。图像通过CLIP ViT-L视觉编码器编码,通过线性投影W映射到语言模型的词嵌入空间,与语言词嵌入拼接后输入LLM。
模型架构:遵循"最小修改"原则,包含三个组件。
- 视觉编码器(Vision Encoder): 采用预训练CLIP ViT-L/14,参数冻结。该模型将图像输入转换为图像特征
- 跨模态桥接器(Cross-modal Connector): LLaVa中叫做投影层(Projection Layer),是一个简单的线性投影矩阵W,将图像特征映射到LLM的词嵌入空间。
- 大型语言模型(Large Language Model): 采用Vicuna (基于shareGPT会话微调的LLaMA),进行端到端微调。该模型将图像词嵌入和语言词嵌入的拼接结果转换为输出文本。然后,通过该输出文本与期望输出文本计算loss。
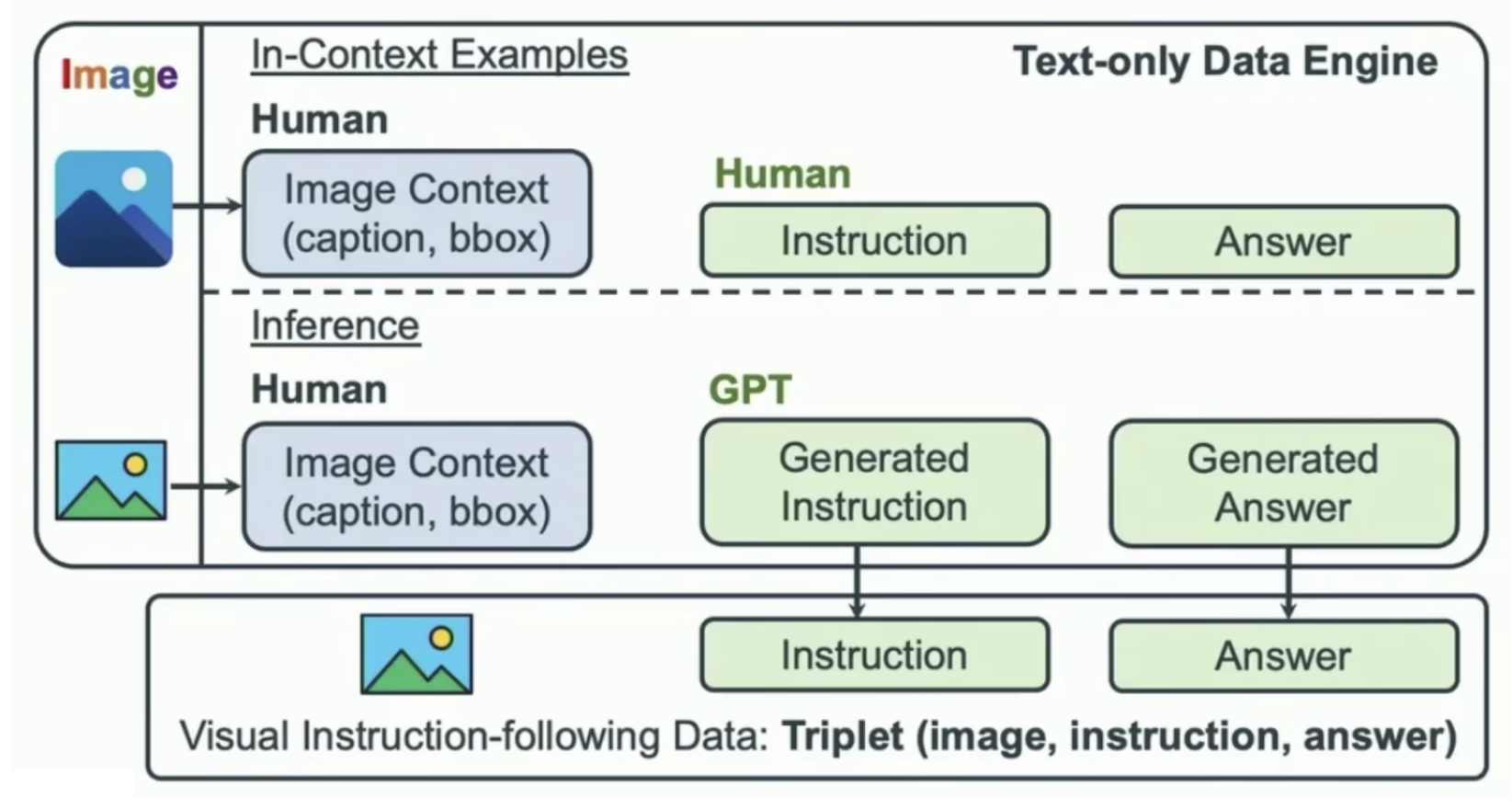
指令数据生成:
LLaVA利用仅支持文本输入的 GPT-4 或 ChatGPT 作为强大的教师模型(两者均只接受文本输入),来生成涉及视觉内容的指令跟随数据。具体而言,
- 为了将图片编码为视觉特征以提示 GPT生成数据,LLaVA使用两种类型的符号表示:(i) 图像描述(Captions),通常从多个角度描述视觉场景;(ii) 边界框(Bounding boxes),用于定位场景中的物体,每个边界框编码了物体概念及其空间位置。
- 人工选择一些图片,基于这些图片的Captions和Bounding boxes,人工生成instruction和answer,这些Captions,Bounding boxes,instruction和answer作为提示GPT-4的上下文,来为未标注图片生成instruction和answer。
视觉指微调: LLaVA的核心创新在于提出了视觉指令微调:
- 数据构建: 使用GPT-4将图像的标题和边界框信息转换为多轮对话格式的指令跟随数据。
- 端到端训练: (两个阶段都不训练视觉编码器):
- 第一阶段(图文特征对齐训练):冻结视觉编码器和语言模型,仅训练Cross-modal Connector(也即图中的 projection ),使用Conceptual Captions数据(过滤CC3M为 595K的图文对)。该阶段可以理解为训练一个与LLM兼容的visual tokenizer。
- 第二阶段(图文指令微调):冻结视觉编码器,通过两个任务端到端微调Cross-modal Connector和语言大模型,让LLaVA学习多模态指令遵循的能力:
- 视觉对话:使用GPT-4辅助生成的约15.8万条多模态指令-响应对(LLaVA-instruct-158K)。
- 科学问答:使用科学领域的多模态推理数据集。
与历史模型的关系:与BLIP-2类似,LLaVA仍然使用了一个跨模态桥接器来连接image encode输出的图像特征和language encoder需要的文本特征。不同的是LLaVA采用一个包含一层MLP的投影层来桥接视觉编码器和文本解码器。与BLIP-2的Q-Former桥接方式相比,LLaVA的线性投影更加简单直接。将LLM中指令微调的范式应用于图像问答和推理。
技术影响: LLaVA的极简架构和视觉指令调优范式证明了多模态大模型不需要复杂的融合模块。后续LLaVA 1.5通过改进数据质量和训练策略进一步提升了性能,LLaVA-NeXT(LLaVA 1.6)引入了更高分辨率的图像处理和更强的推理能力,持续推动开源多模态大模型的发展。
LLaVA的后续改进:
- LLaVA-1.5 (2023年10月):通过三个关键改进显著提升了性能:(1) 将线性投影替换为两层MLP(带GELU激活);(2) 将输入分辨率提升至336x336;(3) 引入面向学术任务的VQA数据。
- LLaVA-NeXT / 1.6 (2024年1月):引入动态高分辨率机制,将输入分辨率提升至原来的4倍(最高672x672)。扩展LLM主干支持Mistral-7B、Qwen-1.5-72B/110B以及LLaMA3 8B等更强的语言模型。
引领了Image + Text -> Text的Large Vision Model的架构与指令训练范式:Vision Encoder + Cross-Modal Connector + LLM
- Vision Encoder 用于从图片中提取图像特征,
- Cross-Modal Connector 用于桥接图像特征和大语言模型需要的文本特征。
- Large Language Model (LLM) 用于处理语言词嵌入和桥接后的图像词嵌入。
除了以上3个核心模块,LLaVA需要对原始的图片和文本进行处理:
- Image Processing:预处理输入图片。将图片切片,形成patch tokens。
- Text Embedding:将输出文本转换为Text embedings。
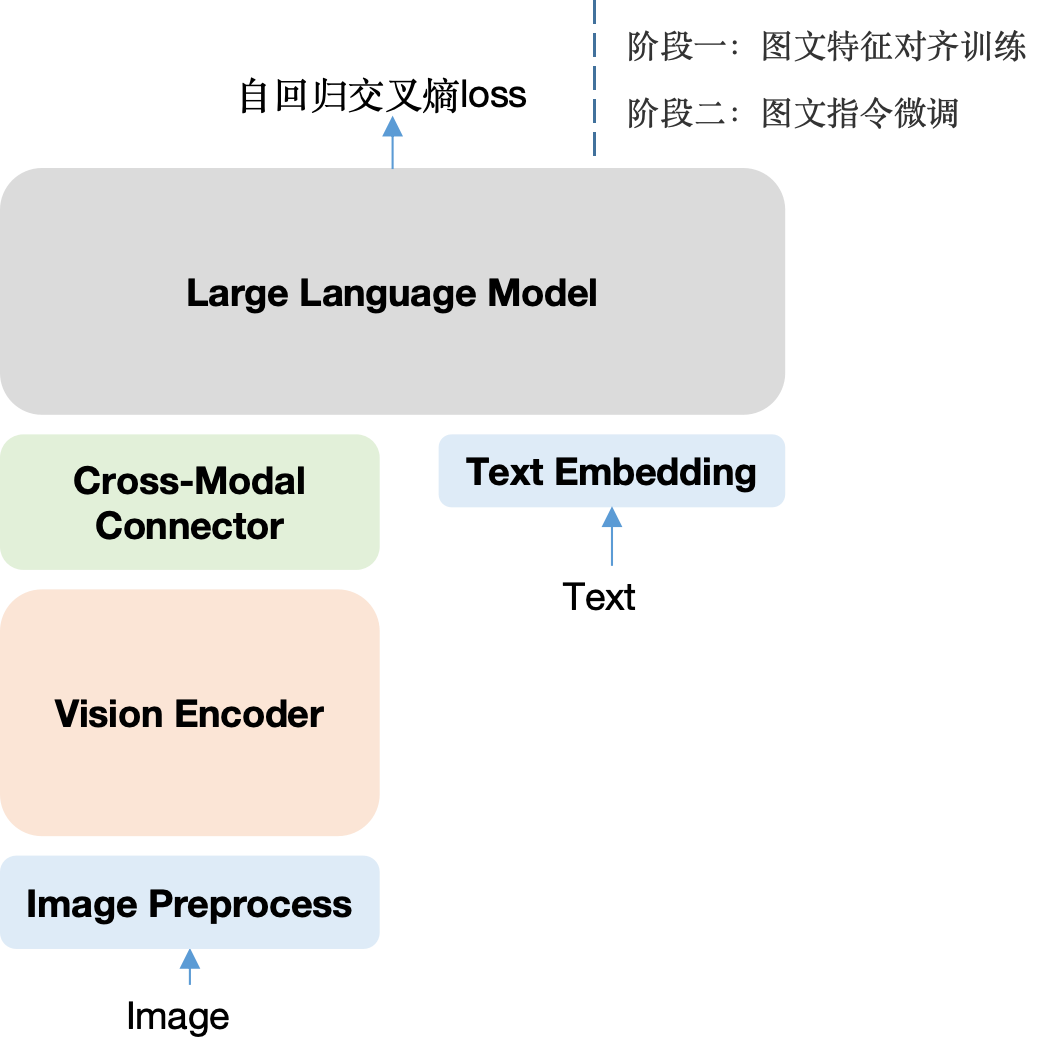
在后续很多开源多模态模型(如,Qwen-VL系列,DeepSeek系列,Gemma系列等)都采用了这种模型架构。
4.3 Qwen-VL:阿里巴巴的多模态大模型
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond发布于2023年8月(arXiv)
核心贡献: Jinze Bai等人(阿里云)提出的Qwen-VL(Qwen Vision-Language)[^15^]是阿里巴巴开源的多模态大模型系列,展现了强大的多语言视觉理解能力、细粒度视觉定位和OCR能力。
Qwen-VL的架构包含三个核心组件:
- 视觉编码器(Vision Encoder): 采用Vision Transformer架构,初始化为OpenCLIP的ViT-bigC(14x14 patches)。
- 跨模态桥接器(Cross-modal Connector):在Qwen-VL中,Cross-modal Connector为一个视觉-语言适配器(Position-aware VL Adapter)。 该适配器采用类似BLIP-2中的Q-Former结构,他包含一个随机初始化的单层交叉注意力模块,并且使用一组**可训练向量(嵌入向量)**作为查询向量(Query),以视觉编码器输出的图像特征作为键(Key),执行交叉注意力运算。该适配器旨在将视觉特征对齐到语言模型的输入空间。
- 语言模型(LLM): 基于Qwen-7B大语言模型。
多阶段训练:
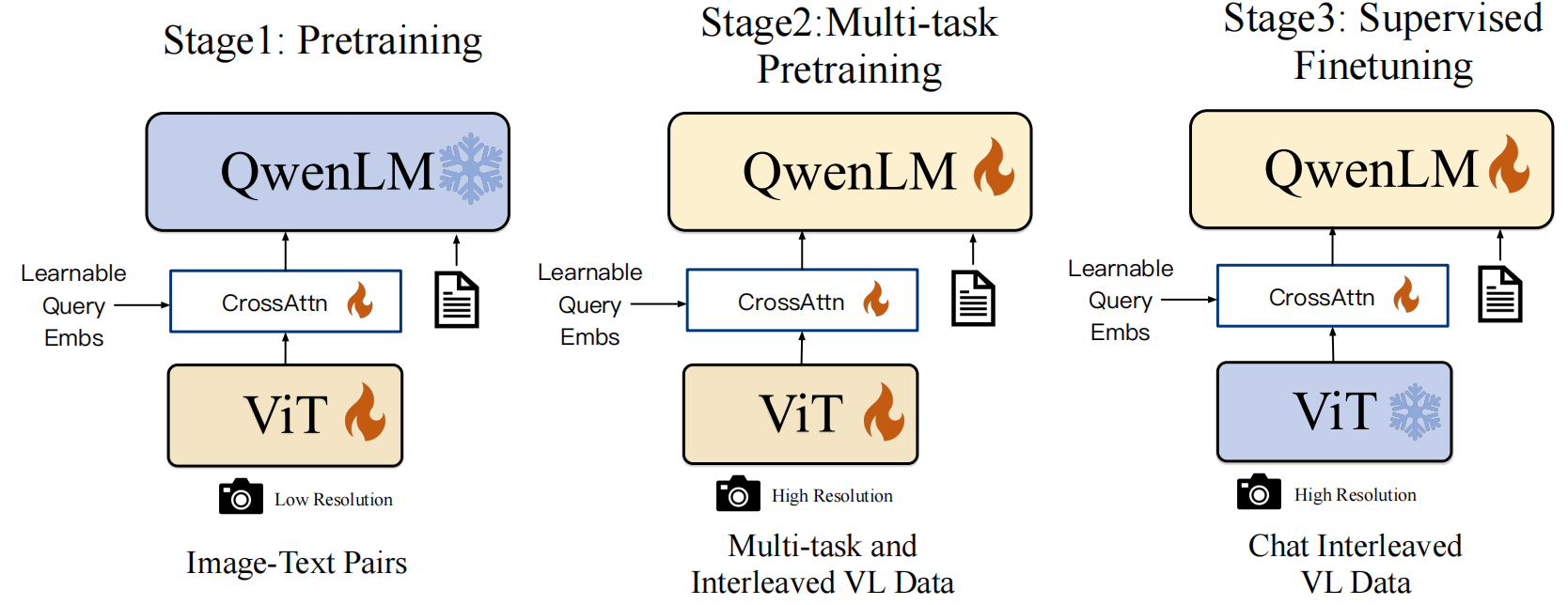
- 阶段一:图片文字预训练。 使用大规模图像-文本对进行预训练,学习基础的视觉-语言对齐。在这个阶段,只训练Vision Encoder和Cross-modal Connector,LLM被冻结。
- 阶段二:多任务预训练。 引入VQA、OCR、视觉定位等多种任务数据进行联合训练。在这个阶段,训练所有模型,包括Vision Encoder,VL Cross-modal Connector,和LLM。
- 阶段三:指令微调。 使用高质量的指令跟随数据进行微调,提升对话和指令遵循能力。在这个阶段,训练VL Adapter和LLM,Vision Encoder被冻结。
技术影响: Qwen-VL在多项基准测试上取得了当时的最先进结果,特别是在中文多模态理解和文档OCR方面表现突出。
与历史模型的关系:使用类似BLIP-2中的Q-Former模块来桥接视觉编码器和文本解码器。
4.4 Qwen2-VL
Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution发布于2024年9月(arXiv)
Qwen2-VL沿用Qwen-VL的架构(但是做了改进)包含三个核心组件:
- 视觉编码器(Vision Encoder): 参数量为675M的Vision Transformer。
- 处理任意分辨率的图像并将其动态转换为可变数量的视觉 token,
- Qwen2-VL的视觉编码器中移除了Qwen-VL的绝对位置嵌入,引入2D-RoPE(旋转位置嵌入)以捕获图像的二维位置信息。
- 跨模态桥接器(Cross-modal Connector):在Qwen2-VL中,Cross-modal Connector是一个名为Patch Merger的模块。该模块包含两层MLP,他将视觉编码器的输出压缩为patch embedding。
- 语言模型(LLM): 采用Qwen2-1.5B, Qwen2-7B 和 Qwen2-72B大语言模型。采用多模态旋转位置嵌入(M-RoPE)来处理LLM的输入。M-RoPE将传统1D-RoPE扩展为三维表示(时间T, 高度H, 宽度W),从而可以处理多个模态的输入(比如,文本,图片和视频)。
| 模型名称 | 视觉编码器 | 大语言模型 | 模型描述 |
|---|---|---|---|
| Qwen2-VL-2B | 675M | 1.5B | 最高效的模型,专为设备端运行设计。在资源受限的情况下,仍能为大多数场景提供足够的性能。 |
| Qwen2-VL-7B | 675M | 7.6B | 在成本方面性能最优的模型,文本识别和视频理解能力显著提升。在广泛的视觉任务中均表现出色。 |
| Qwen2-VL-72B | 675M | 72B | 能力最强的模型,在视觉推理、指令遵循、决策制定和智能体能力方面进一步提升。在大多数复杂任务上表现最优。 |
多阶段训练(采用 Qwen-VL的三阶段训练方法):
- 阶段一:专注于训练Vision Encoder和Cross-modal Connector,冻结LLM。利用海量的图像-文本对语料来增强大语言模型(LLM)的语义理解能力。
- 阶段二:解冻所有参数,使用更广泛的数据进行训练,以实现更全面的学习。
- 阶段三:使用指令数据集仅对大语言模型(LLM)进行微调。
技术影响: 在Qwen-VL的基础上,引入了动态分辨率视觉Transformer和窗口注意力机制,支持更高效的高分辨率图像处理和长视频理解。
与历史模型的关系:
与Qwen-VL的关系(架构继承与显著改进):
Qwen2-VL是Qwen-VL的直接继任者,在架构上继承了Qwen-VL的视觉编码器+适配器+大语言模型的基本框架,但进行了多项关键改进:
- 视觉编码器升级:Qwen-VL使用OpenAI的CLIP ViT-L/14作为视觉编码器,而Qwen2-VL采用了自研的ViT(Vision Transformer),支持Naive Dynamic Resolution(原生动态分辨率),可以处理任意分辨率的图像
- 位置编码改进:Qwen2-VL引入了多模态旋转位置编码(M-RoPE),将标准RoPE扩展为三个组成部分(高度、宽度、时间/通道),使模型能够同时感知1D文本、2D图像和3D视频中的空间关系
- 视频理解能力:Qwen2-VL将视频处理原生集成到架构中,支持长达数小时的视频序列理解,而Qwen-VL的视频能力有限
- 模型规模扩展:Qwen2-VL提供了2B、7B、72B三个规模版本,而Qwen-VL主要提供7B和9B版本
与LLaVA系列的关系(同为LLaVA-style架构):
Qwen2-VL与LLaVA系列(LLaVA 1.0/1.5/1.6/NeXT)同属LLaVA-style架构——即使用预训练的视觉编码器提取图像特征,通过轻量级适配器(adapter/projector)将视觉特征投影到语言模型的输入空间,再由大语言模型进行理解和推理。两者的核心差异在于:
- 视觉处理:LLaVA系列使用CLIP ViT进行图像编码,通过简单的线性层或MLP projector进行模态对齐;Qwen2-VL使用自研ViT并支持动态分辨率
- 位置编码:Qwen2-VL的M-RoPE是其独特创新,LLaVA系列使用标准RoPE或标准位置编码
- 训练策略:LLaVA系列强调"低训练成本快速适配",Qwen2-VL则进行了更大规模的多阶段预训练
- 上下文长度:Qwen2-VL支持128K tokens的上下文窗口,显著优于早期LLaVA版本
与InternVL等动态分辨率模型的关系:
Qwen2-VL的Naive Dynamic Resolution机制与InternVL系列的动态分辨率处理有相似之处——两者都旨在解决固定分辨率导致的信息丢失问题。InternVL采用将图像切分为多个448x448 patch的方式处理高分辨率图像,而Qwen2-VL采用更简洁的策略:将图像缩放到合适的尺寸后,按固定patch size切分,直接送入ViT处理。Qwen2-VL的方案更加简洁高效,避免了InternVL中复杂的patch合并和特殊token设计。此外,Qwen2-VL在处理多图场景和视频序列时展现了更强的连贯性,这得益于其M-RoPE位置编码机制。
Qwen2.5-VL的改进:
- 从头训练的ViT视觉编码器:引入Window Attention,LayerNorm→RMSNorm,GELU→SwiGLU。
- 双层MLP视觉-语言融合器:增强模态对齐能力。
- 动态FPS采样:根据视频时长动态调整采样帧率。
- 绝对时间编码:实现秒级事件定位能力。
- 语言模型(LLM):Qwen2.5-3B/7B/32B/72B,预训练数据4 trillion token
4.5 Qwen3-VL
Qwen3-VL Technical Report发布于2025年11月(arXiv)
Qwen3-VL 架构模块详:
- 视觉编码器:采用400M参数的SigLIP2-SO-400M,支持动态输入分辨率,使用2D-RoPE并遵循CoMP方法插值绝对位置嵌入。
- 跨模态桥接器(Cross-modal Connector):Qwen3-VL采用双层MLP融合器 + DeepStack机制。两层MLP将2x2视觉patch压缩为单个token。DeepStack通过轻量级残差连接将视觉编码器中间层的视觉token注入LLM的对应层,保留从低级边缘到高级语义的多层次视觉信息。
- Interleaved-MRoPE 交错式多模态旋转位置嵌入:Qwen2.5-VL的M-RoPE将嵌入维度划分为t/h/v三个子空间导致频率谱不平衡。Interleaved-MRoPE通过均匀交错分布t/h/v组件在嵌入维度中,确保高低频段平衡分配。
- Text-Timestamp Alignment 文本时间戳对齐:替代T-RoPE,改用显式文本时间戳标记(如
<3.0 seconds>)表示视频中的时间位置,实现更精确的时间定位。 - 语言模型(LLM):Dense变体(2B/4B/8B/32B)和MoE变体(30B-A3B/235B-A22B)。原生256K上下文(可扩展到1M)。支持非思考和思考两种模式。
多阶段训练(Qwen3-VL采用四阶段训练方法):
| 维度 | 阶段一 对齐 | 阶段二 全面学习 | 阶段三 长上下文 | 阶段四 超长上下文 |
|---|---|---|---|---|
| 核心目标 | 模态桥接 | 通用多模态能力 | 长序列处理 | 极限长序列 |
| 训练策略 | 仅训练 Merger(冻结其它模块) | 全参数端到端 | 全参数 + 序列扩4倍 | 全参数 + 序列扩至 262k |
| 数据特点 | 精选高质量(图像-标题、OCR) | 大规模混合(VL + 文本 + 视频) | 增加视频与 Agent 数据 | 聚焦长视频与长文档 |
| Token 量 | 67B | ~1T | ~1T | 100B |
| 序列长度 | 8,192 | 8,192 | 32,768 | 262,144 |
4.6 DeepSeek-VL:面向真实世界的视觉-语言理解(2024年3月)
DeepSeek-VL: Towards Real-World Vision-Language Understanding 由 DeepSeek-AI 于2024年3月提出(arXiv),Haoyu Lu、Wen Liu、Bo Zhang 等人联合发表。
核心贡献: DeepSeek-VL 是 DeepSeek 团队推出的开源视觉-语言模型(VLM),旨在解决真实世界场景中的视觉-语言理解问题。其核心贡献包括三个方面:(1)混合视觉编码器设计——结合低分辨率语义编码器(SigLIP-L)和高分辨率细节编码器(SAM-B),在固定 token 预算内高效处理 1024×1024 高分辨率图像,同时捕获高层语义和低级细节;(2)模态平衡训练策略——提出"模态渐进"(modality warm-up)策略,通过从纯文本数据开始逐步增加视觉-语言数据比例,并维持约 30% 纯文本数据,有效避免多模态预训练过程中的语言能力灾难性遗忘;(3)真实世界数据体系——构建覆盖网页截图、PDF 文档、OCR、图表、专业知识等真实场景的大规模预训练数据集,并基于实际用户场景建立用例分类体系来指导指令微调数据的构建。
模型架构:
DeepSeek-VL 的整体架构采用经典的类 LLaVA 解码器架构,由三个核心模块组成:混合视觉编码器(Hybrid Vision Encoder)、视觉-语言适配器(Vision-Language Adaptor)和语言模型(LLM)。
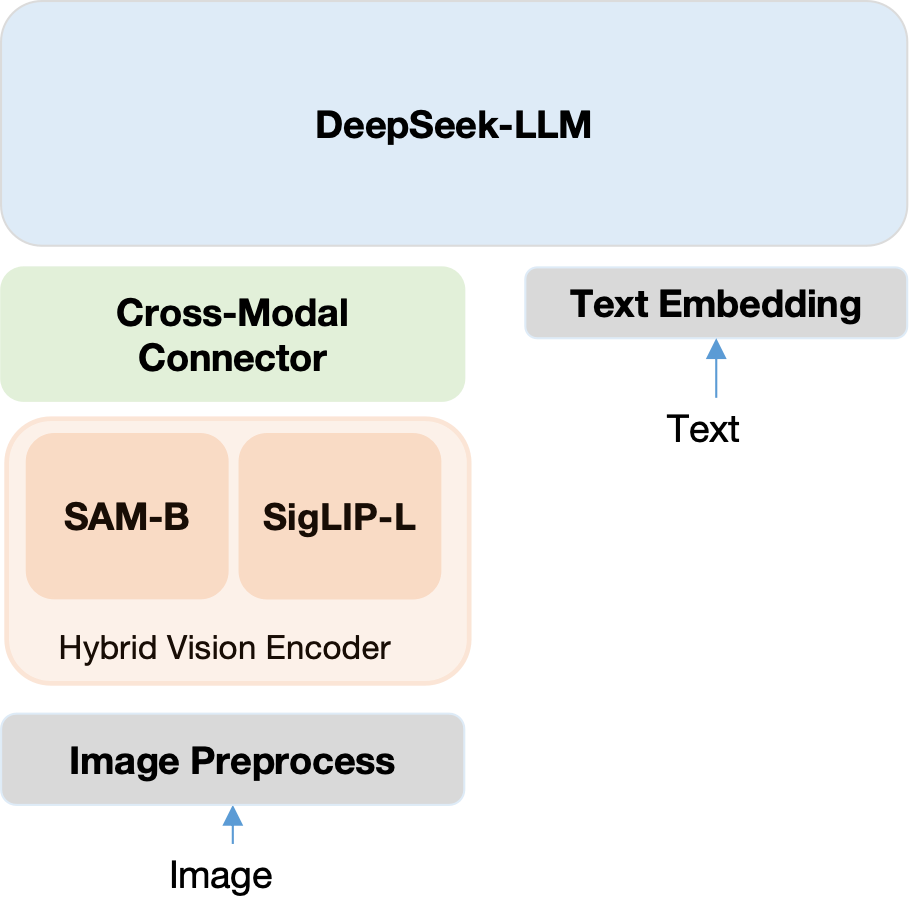
-
混合视觉编码器:
DeepSeek-VL 采用双编码器混合架构来同时捕获语义信息和细节信息,两个编码器并行处理,输出特征在通道维度拼接:-
SigLIP-L 视觉编码器(低分辨率路径):基于 SigLIP SoViT-384-14 模型,处理 384×384 分辨率的输入图像,用于提取高层语义特征表示。SigLIP 是一种改进的 CLIP 风格对比学习视觉编码器,其特征与文本空间已经过预训练对齐。该编码器将 384×384 图像编码为 24×24×1024 的特征图,最终 reshape 为 576×1024 的特征序列。
-
SAM-B 视觉编码器(高分辨率路径):基于 SAM(Segment Anything Model)的 ViTDet 骨干网络,处理 1024×1024 分辨率的高分辨率输入,专门用于捕获低级细节特征(如小物体、文字、UI 元素等)。SAM-B 首先生成 64×64×256 的特征图,然后通过 VL Adaptor 进行插值到 96×96×256,再经过两个 stride=2 的卷积层下采样到 24×24×1024,最终 reshape 为 576×1024 的特征序列。
两个编码器输出的 576×1024 特征在维度上拼接(concatenate),形成 576 个视觉 token,每个 token 维度为 2048。这种设计将 1024×1024 的高分辨率图像高效压缩为固定数量的视觉 token,在视觉丰富度和 token 经济性之间取得平衡。
-
-
视觉-语言桥接器(Cross-modal Connector):
采用两层混合 MLP 作为跨模态桥接器:- 第一层:两个独立的单层 MLP 分别处理高分辨率特征(SAM-B 输出)和低分辨率特征(SigLIP-L 输出);
- 第二层:将处理后的特征拼接并通过另一个单层 MLP 投影到 LLM 的输入嵌入空间;
- 激活函数使用 GeLU。
这种混合 MLP 设计允许模型分别处理不同分辨率的特征,再统一映射到语言模型的输入空间。
-
语言模型:
语言模型基于 DeepSeek-LLM,其微观设计遵循 LLaMA 架构:- Pre-Norm 结构,使用 RMSNorm 归一化;
- 激活函数使用 SwiGLU,FFN 中间层维度为 ;
- 位置编码使用旋转位置编码(Rotary Embedding, RoPE);
- 使用与 DeepSeek-LLM 相同的分词器;
- 提供两个规模版本:
- DeepSeek-VL-1.3B:基于 DeepSeek-LLM-1B(预训练约 5000 亿文本 token)
- DeepSeek-VL-7B:基于 DeepSeek-LLM-7B(预训练约 2 万亿文本 token)
训练方法:
DeepSeek-VL 采用三阶段训练策略:
| 阶段 | 名称 | 训练参数 | 数据 | 关键设计 |
|---|---|---|---|---|
| Stage 1 | VL 适配器预热 | 仅 VL 适配器(视觉编码器和 LLM 冻结) | 125万 ShareGPT4V 图像-文本对 + 250万 Document OCR 渲染对 | 建立视觉与语言元素的概念联系 |
| Stage 2 | 联合 VL 预训练 | VL 适配器 + LLM(视觉编码器冻结) | ~70% 视觉-语言数据 + 30% 纯文本数据 | 模态平衡防止语言能力遗忘 |
| Stage 3 | 监督微调(SFT) | SigLIP-L + VL 适配器 + LLM(SAM-B 冻结) | 多模态 SFT 数据 + DeepSeek-LLM 纯文本对话数据 | 增强指令遵循和对话能力 |
各阶段详细说明:
Stage 1 —— 视觉-语言适配器预热:目标是在嵌入空间建立视觉元素与语言元素之间的概念联系。此阶段冻结混合视觉编码器和 LLM,仅训练 VL 适配器。实验发现,此阶段的数据量并非越多越好,过度扩展数据反而可能降低性能。
Stage 2 —— 联合视觉-语言预训练:目标是在 LLM 基础上发展全面的多模态理解能力。关键发现是直接用 100% 多模态数据训练会导致严重的语言能力遗忘,因此采用联合语言-多模态训练策略,使用约 70% 视觉-语言数据 + 30% 纯文本数据的混合比例,有效缓解语言能力退化。使用多选困惑度(Multi-choice PPL)方法监控训练进度,并加入少量 SFT 数据帮助模型学习遵循指令。7B 模型在此阶段训练约 42000 步,batch size 约 2304。
Stage 3 —— 监督微调(SFT):目标是增强指令遵循能力和对话能力。仅对答案和特殊 token 计算损失,系统和用户提示被 mask。使用多模态 SFT 数据与 DeepSeek-LLM 的纯文本对话数据混合训练。
预训练数据组成(Stage 2):
| 数据类别 | 占比 | 来源 |
|---|---|---|
| 纯文本语料 | ~70% | DeepSeek-LLM 2T 文本语料 |
| 交错图文数据 | ~13.1% | MMC4、Wikipedia、Wikihow、内部 PDF/Epub 教材 |
| 图像描述数据 | ~11.1% | Capsfusion、TaiSu、Detailed Caption |
| 表格和图表数据 | ~2.1% | Chart2text、Geo170K、Ureader、Unichart、M-paper、ScienceQA、ScreenQA 等 |
| 网页代码数据 | ~0.4% | Websight、GitHub Jupyter Notebook Python 图表 |
| 场景文本 OCR | ~1.2% | ArT、MLT-17、LSVT、UberText、COCO-Text、RCTW-17 等 |
| 文档 OCR | ~2.1% | arXiv 渲染 Markdown、内部文档 |
SFT 数据(Stage 3) 涵盖开源多模态数据集(ShareGPT4V、LAION-GPTV、LVIS-Instruct4V 等)、表格图表数据、UI 代码数据,以及基于真实用户场景构建的内部高质量 SFT 数据,覆盖识别、转换、分析、推理、评估、安全等多类别。
与历史模型的关系:
- 继承 LLaVA 架构范式:DeepSeek-VL 采用与 LLaVA 相同的解码器-only、视觉编码器+适配器+LLM 的架构路线,属于 LLaVA-style 架构的延续。
- 改进视觉编码:不同于 LLaVA 使用单一 CLIP 视觉编码器,DeepSeek-VL 引入双编码器混合架构(SigLIP+SAM),解决单一编码器在细节捕捉上的不足。相比 BLIP-2 使用 Q-Former 作为跨模态桥接器,DeepSeek-VL 采用更简单的 MLP 适配器。
- 延续 DeepSeek-LLM 基础:语言模型底座来自 DeepSeek-LLM,继承其架构设计和语言能力。
- 数据构建借鉴:适配器预热阶段借鉴 LLaVA 和 Instruct-BLIP 的做法,同时引入文档 OCR 数据增强对高分辨率文档的理解。
技术影响: DeepSeek-VL 为后续的开源 VLM 发展提供了重要参考:其混合视觉编码器的设计思路(结合语义编码器和细节编码器)被后续多个模型借鉴;模态平衡训练策略(保持 30% 以上语言数据)成为防止多模态训练中语言能力退化的标准做法之一;基于真实用户场景构建 SFT 数据的方法也影响了后续模型的数据构建策略。该模型在 1.3B 和 7B 规模上均在多项视觉-语言基准测试中取得了同等规模模型中的 SOTA 或竞争性表现。
4.7 DeepSeek-VL2:混合专家视觉-语言模型(2024年12月)
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding 由 DeepSeek-AI 于2024年12月提出(arXiv),Zhiyu Wu、Xiaokang Chen、Zizheng Pan 等人联合发表。
核心贡献: DeepSeek-VL2 是 DeepSeek-VL 的重大升级版本,引入了两大核心创新:(1)动态分块视觉编码策略——用单一 SigLIP 编码器配合动态图像分块机制替代了前代的双编码器混合架构,能够高效处理任意高分辨率图像和不同宽高比的输入,解决了固定分辨率编码器在处理信息图、密集 OCR 和视觉定位等任务时的局限性;(2)MoE 架构与多头隐注意力机制——采用 DeepSeekMoE 作为语言模型底座,配合 Multi-head Latent Attention(MLA)机制将 Key-Value 缓存压缩为隐向量,实现高效推理和高吞吐量。模型在视觉问答、OCR、文档/表格/图表理解以及视觉定位等多项任务上展现出卓越能力,同时提供了 Tiny、Small 和 Base 三个规模版本以适应不同部署场景。
模型架构:
DeepSeek-VL2 延续了三模块架构(视觉编码器、VL 适配器、语言模型),但对其进行了全面升级。
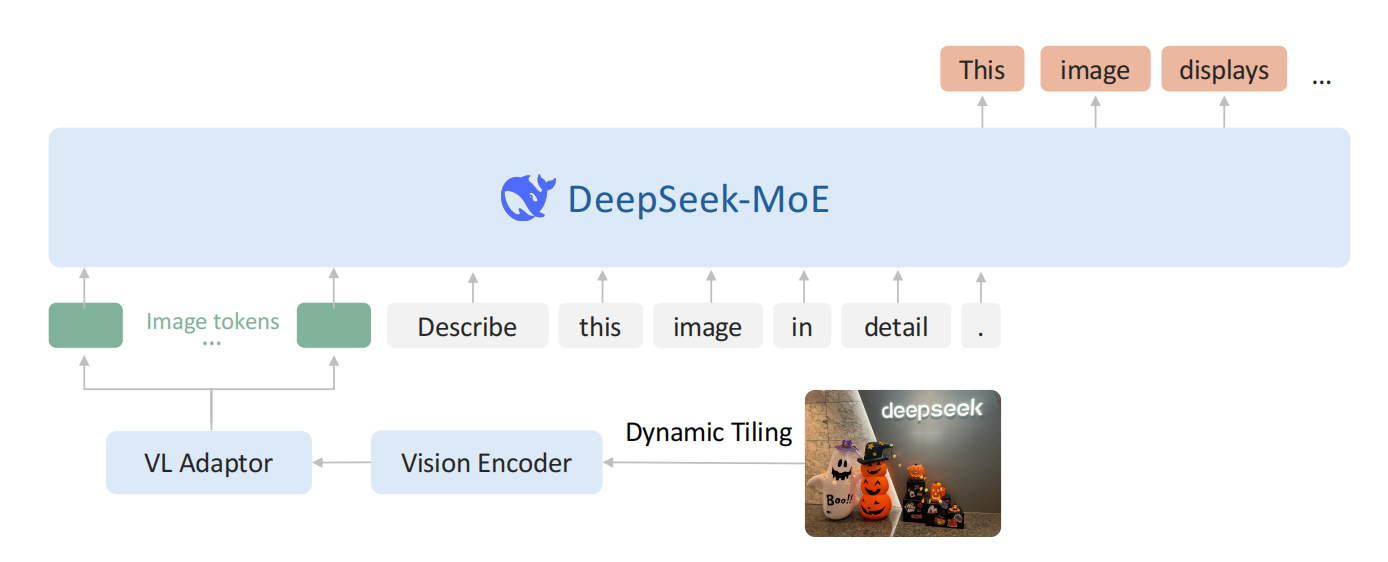
-
视觉编码器(动态分块策略):
DeepSeek-VL2 放弃了前代的双编码器设计,改为使用单一 SigLIP-SO400M-384 视觉编码器配合动态分块策略:- 基础编码器:使用预训练的 SigLIP-SO400M-384,基础分辨率为 384×384。
- 候选分辨率集合:定义一组候选分辨率 ,即支持从 1×1 到最多 3×3 共 9 个图块的组合。
- 动态分块(Dynamic Tiling Strategy)流程:
- 对于输入图像 ,计算将其 resize 到每个候选分辨率所需的填充面积;
- 选择填充面积最小的候选分辨率 ;
- 将 resize 后的图像分割为 个 384×384 的局部图块(tiles);
- 额外生成一个全局缩略图(global thumbnail);
- SigLIP 编码器处理所有 个图块,每个图块产生 27×27=729 个 1152 维的视觉嵌入。
- Token 压缩:使用 2×2 pixel shuffle 将每个图块的视觉 token 从 27×27 压缩到 14×14=196 个 token。
- 特殊 Token:引入三类特殊 token——全局缩略图每行末尾添加
<tile_newline>token(共 14×15=210 个 token);局部图块网格在最右列添加<tile_newline>token;全局图与局部图块之间插入<view_separator>token。 - 多图优化:当处理超过 2 张图像时,禁用动态分块策略以保证计算效率。
相比 DeepSeek-VL 的固定 1024×1024 双编码器方案,动态分块策略可以处理更大分辨率和极端宽高比的图像,同时避免了双编码器的计算开销。
-
VL 适配器:
- 采用两层 MLP 将视觉 token 投影到语言模型的嵌入空间。
- 完整视觉序列的 token 数为:。
- 相比前代简化了架构(不再需要分别处理高/低分辨率特征的混合 MLP)。
-
MoE 语言模型(DeepSeekMoE with MLA):
语言模型基于 DeepSeekMoE 架构,并引入了 Multi-head Latent Attention(MLA) 机制:
- MLA 机制:通过将 Key-Value 缓存压缩为隐向量(latent vectors),显著提升推理效率和吞吐量。
- MoE 架构:使用稀疏计算实现高效推理,每个 token 仅激活部分专家。
- 负载均衡:引入全局偏置项(global bias term)来改善专家间的负载均衡。
- 三个规模版本:
模型 总参数量 激活参数量 词表大小 嵌入维度 注意力头数 层数 注意力类型 专家数 推荐部署显存 DeepSeek-VL2-Tiny ~3B 1.0B 129,280 1,280 10 12 Multi-Head Attention 64 10GB DeepSeek-VL2-Small ~16B 2.8B 102,400 2,048 16 27 MLA (rank=512) 64 40GB DeepSeek-VL2 ~27B 4.5B 129,280 2,560 32 30 MLA (rank=512) 72 80GB
训练方法:
DeepSeek-VL2 采用与 DeepSeek-VL 类似的三阶段训练流程,但有重要改进:
| 阶段 | 名称 | 训练参数 | 数据 | 关键设计 |
|---|---|---|---|---|
| Stage 1 | VL 对齐 | 视觉编码器 + VL 适配器(LLM 冻结) | ShareGPT4V(~120万图像-文本对) | 同时优化视觉编码器和适配器 |
| Stage 2 | VL 预训练 | 全部参数解冻 | ~8000亿图像-文本 token,70% VL + 30% 纯文本 | 全面发展联合 VL 知识 |
| Stage 3 | 监督微调(SFT) | 全部参数 | 多模态 SFT 数据 + DeepSeek-V2 纯文本对话数据 | 增强指令遵循和对话能力 |
各阶段详细说明:
Stage 1 —— 视觉-语言对齐(VL Alignment):目标是建立视觉特征与语言特征之间的鲁棒连接。与 LLaVA 和 DeepSeek-VL 不同,此阶段同时优化视觉编码器和 VL 适配器,LLM 保持冻结。这一关键调整使固定分辨率的视觉编码器能够适应动态高分辨率图像输入。
Stage 2 —— 视觉-语言预训练:目标是发展全面的联合视觉-语言知识。所有参数全部解冻(视觉编码器、VL 适配器 MLP、DeepSeekMoE LLM),使用约 8000 亿 图像-文本 token 进行训练,数据比例维持约 70% 视觉-语言数据 + 30% 纯文本数据(来自 LLM 预训练语料),在增强多模态理解能力的同时保持大部分语言能力。
Stage 3 —— 监督微调(SFT):目标是增强指令遵循和对话能力。优化所有参数,仅监督答案和特殊 token,mask 系统和用户提示。多模态 SFT 数据与 DeepSeek-V2 的纯文本对话数据混合训练,覆盖密集图像描述、通用 VQA、OCR、表格/图表/文档理解、视觉到代码转换、视觉推理、视觉定位、语言理解等任务。
预训练数据组成(Stage 2):
| 数据类别 | 说明 |
|---|---|
| 交错图文数据 | WIT、WikiHow、OBELICS 30% 随机采样、Wanjuan(中文)、内部收集 |
| 图像描述数据 | 开源数据集重新标注(使用 OCR 提示、元信息、原始描述作为提示),经质量评分过滤 |
| OCR 数据 | LaTeX OCR、RenderedText 12M、大规模内部 OCR 数据集(中英文为主) |
| 视觉问答(VQA) | 通用 VQA、表格/图表/文档理解(PubTabNet、FinTabNet、Docmatix)、网页到代码、带视觉提示的 QA |
| 视觉定位数据 | 目标检测标注结构化,支持定位特定物体 |
| 基础对话数据 | 结合视觉定位的对话能力 |
| 纯文本数据 | 来自基础 LLM 预训练语料,占比约 30% |
与历史模型的关系:
- 继承 DeepSeek-VL:DeepSeek-VL2 直接继承自 DeepSeek-VL,保留了三模块的整体架构设计思路,并在数据构建上延续了 70/30 的视觉-语言/纯文本数据比例策略。
- 改进视觉编码:放弃双编码器(SigLIP+SAM)方案,改用单一 SigLIP 编码器+动态分块策略,解决了固定分辨率限制,简化了架构同时提升了高分辨率处理能力。
- 升级语言模型底座:从 DeepSeek-LLM(Dense 架构)升级为 DeepSeekMoE(稀疏 MoE 架构),配合 MLA 注意力机制大幅提升推理效率。
- 延续 LLaVA-style 架构:整体架构仍属于 LLaVA-style 的解码器-only 架构,视觉 token 前置与文本 token 联合输入 LLM。
- 借鉴动态分块思想:动态分块策略借鉴了 InternVL、Qwen-VL 等同期工作的图像分块处理方法,但进行了适应性改进。
技术影响: DeepSeek-VL2 代表了高效多模态模型的重要发展方向:通过 MoE 架构实现了激活参数与总参数的解耦,使得 4.5B 激活参数的模型可以达到甚至超越更大 Dense 模型的性能;动态分块视觉编码策略为高分辨率图像处理提供了一种轻量级且高效的解决方案;MLA 注意力机制在 VLM 领域的应用展示了压缩 KV 缓存对推理效率的巨大提升。该模型系列(Tiny/Small/Base 三个版本)为不同资源约束下的应用场景提供了灵活的选择,推动了 MoE 架构在视觉-语言领域的广泛应用。
4.8 Google PaliGemma与Gemma
发布时间: PaliGemma(2024年7月),PaliGemma 2(2024年12月),Gemma 3(2025年3月)
核心贡献: Google的Gemma系列是与Gemini同系列的开源轻量级模型。PaliGemma将SigLIP视觉编码器与Gemma语言模型结合,成为一个多功能的3B参数VLM。Gemma 3则进一步引入了多模态、长上下文和多语言能力。
架构设计:
PaliGemma也采用LLaVA的架构设计:
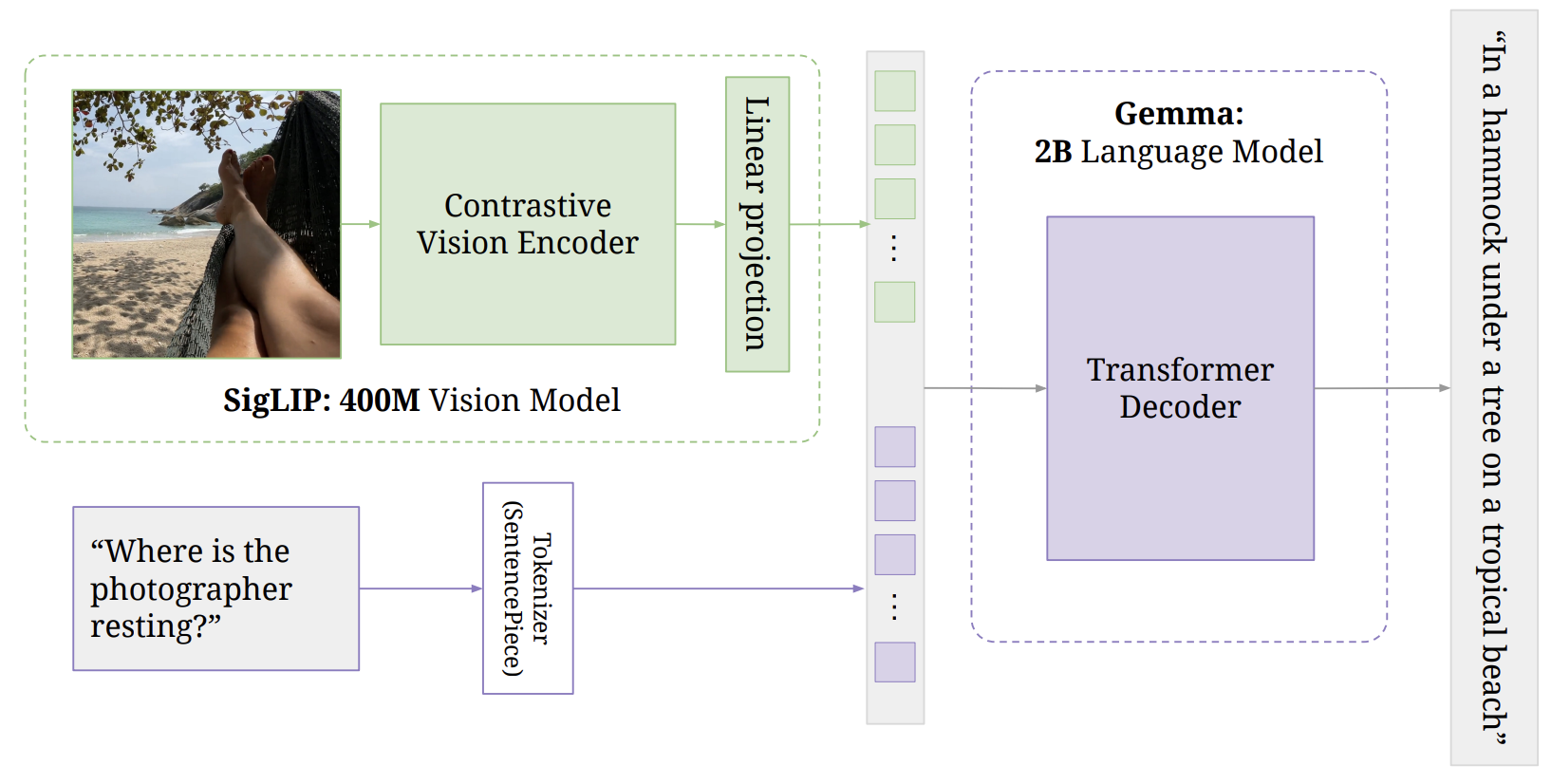
- SigLIP-So400m视觉编码器: 采用Sigmoid损失训练的Vision Transformer,将图像编码为视觉Tokens。
- 线性投影层: 将视觉Tokens投影到Gemma的词嵌入空间(使图像和文本的维度相同)。
- Gemma-2B语言模型: 自回归生成文本输出。
PaliGemma作为Prefix-LM运行:图像Tokens和用户输入(前缀)之间进行完全注意力交互,输出部分则自回归生成。
PaliGemma 2:
PaliGemma 2是Google于2025年发布的PaliGemma升级版,包括PaliGemma 2-3B,PaliGemma 2-10B,PaliGemma 2-28B主要改进包括:
- 语言模型升级:使用Gemma 2语言模型(Gemma-2-2B/9B/27B)替代Gemma 1,语言理解和推理能力大幅增强。
- 多分辨率支持:支持多种输入分辨率,适应不同应用场景的需求
- 开放权重:继续以开放权重形式发布,提供3B参数规模版本,支持学术研究和商业应用
- 任务覆盖:继承并扩展了PaliGemma的长尾视觉-语言能力,在图像描述、视觉问答、OCR、目标检测、语义分割等任务上均有出色表现
Gemma 3的改进包括:
- 多模态支持: 兼容SigLIP视觉编码器,通过Pan and Scan方法支持灵活的分辨率。
- 长上下文: 支持128K Token上下文,采用局部-全局注意力机制降低KV缓存内存开销。
- 知识蒸馏: 所有模型均使用知识蒸馏进行训练。
技术影响: PaliGemma以其紧凑的3B参数规模和强大的多功能性,成为边缘设备和资源受限场景下部署多模态模型的理想选择。Gemma 3则进一步提升了轻量级多模态技术影响: PaliGemma以其紧凑的3B参数规模和强大的多功能性,成为边缘设备和资源受限场景下部署多模态模型的理想选择。Gemma 3则进一步提升了轻量级多模态模型的能力上限,在保持参数规模可控的前提下,实现了接近更大规模模型的视觉理解性能。Google的Gemma系列通过开源策略,极大地降低了多模态AI的准入门槛,使研究者和开发者能够在消费级硬件上运行和微调高质量的多模态模型,推动了边缘AI和端侧智能的普及。
技术影响总结:
Google的Gemma系列(PaliGemma、PaliGemma 2、Gemma 3)代表了开源轻量级多模态模型的重要发展方向。其核心影响体现在三个层面:
- 降低准入门槛:3B参数规模的PaliGemma使个人研究者和中小企业也能部署高质量多模态模型,无需昂贵的GPU集群
- 推动边缘AI:轻量级设计使多模态模型可以在移动设备、嵌入式系统和边缘服务器上运行,加速了AI在物联网和边缘计算场景的普及
- 开源生态建设:Google以开放权重形式发布这些模型,结合Hugging Face等平台的集成支持,构建了活跃的开源多模态社区,推动了从学术界到工业界的广泛采用
4.9 Meta Llama系列的多模态演进
发布时间: Llama 3.2 Vision(2024年9月),Llama 4(2025年4月)
核心贡献: Meta的Llama系列从Llama 3.2开始正式引入多模态能力,Llama 4则标志着Llama系列进入原生多模态时代,采用了混合专家(Mixture of Experts, MoE)架构和早期融合(Early Fusion)策略。
架构设计:
Llama3.2-Vision模型建立在预训练的Llama 3.1纯文本模型之上。它采用标准的Dense自回归Transformer架构,与其前身Llama和Llama 2并无太大差异。为了支持视觉任务,Llama 3.2使用预训练的视觉编码器(ViT-H/14)提取图像表征向量,并使用视觉适配器(vision adapter)将这些图像表征集成到语言模型中。其架构由三大模块组成:
Llama 3.2 Vision(11B / 90B)架构:
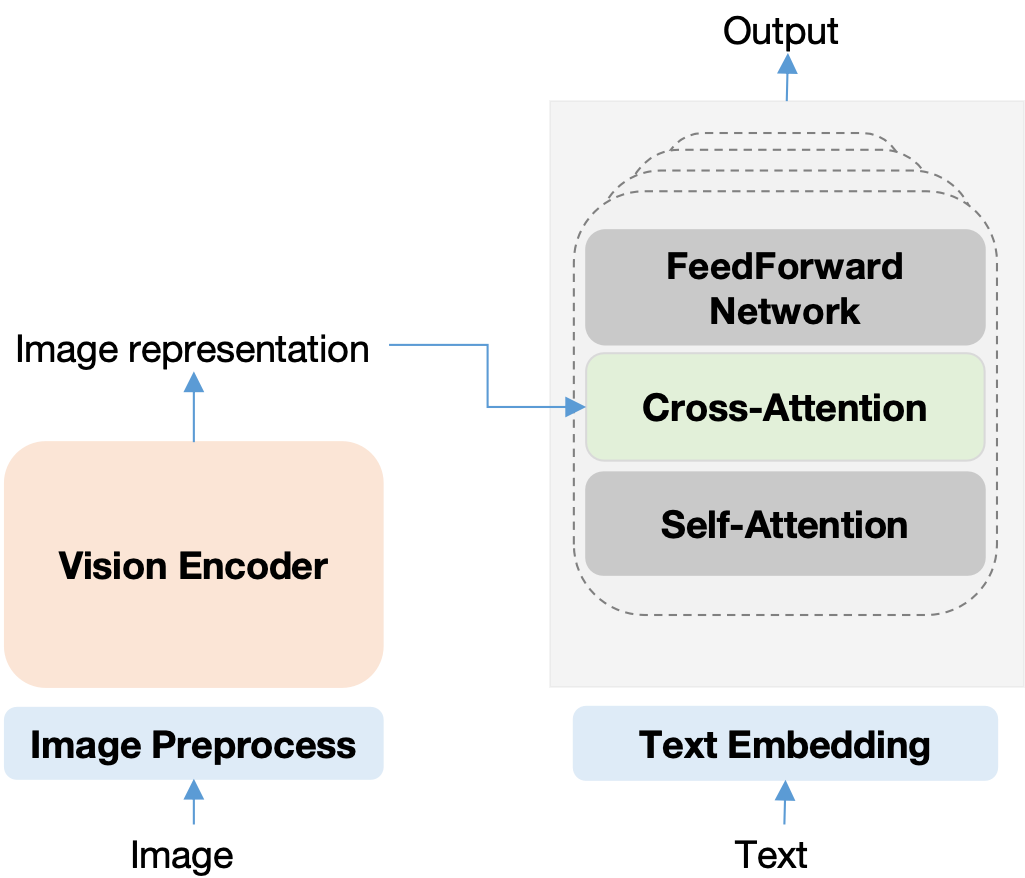
-
视觉编码器(Vision Encoder)。采用 ViT-H/14(Vision Transformer)作为基础图像编码器
-
两阶段架构:包含一个 32 层的局部编码器和一个 8 层的全局编码器,用于提取多尺度视觉特征
-
输入图像被分割为 16×16 像素的 Patch 进行处理
-
支持最高 1120×1120 像素 的高分辨率图像输入
-
图像预处理采用分块(Tiling)机制:大图像被拆分为多个 560×560 的图块(最多 4 个 tiles),并保留宽高比元数据
-
-
视觉适配器(Vision Adapter)。这是 Llama 3.2 Vision 的关键创新,负责桥接视觉与语言模态:
-
由一系列交叉注意力层(Cross-Attention Layers) 组成
-
采用门控交叉注意力(Gated Cross-Attention) 机制,控制视觉信息向文本流的注入强度
-
注入策略:视觉特征并非在输入层简单拼接(早期融合),而是在 LLM 的特定间隔层(如每第 4 层)通过交叉注意力注入到解码器层中
-
适配器训练期间,图像编码器参数会更新,而 Llama 3.1 语言模型参数保持冻结,以保留已有的语言能力
-
-
语言模型主干(Frozen LLM Backbone)。直接继承自 Llama 3.1 的预训练文本模型(11B 和 90B 版本分别对应增强后的 3.1 模型)
Llama 3.2 多阶段训练的核心设计哲学是冻结语言模型、训练Vision Encoder和插入的Vision Adapter,从而在保留 Llama 3.1 强大文本能力的同时增加视觉理解。:
-
预训练。基于 Llama 3.1 文本模型,训练Vision Encoder和Vision Adapter:
- 首先,在大规模噪声(图像,文本)配对数据上训练Vision Encoder和Vision Adapter。
- 然后,在中等规模的高质量领域内和知识增强(图像,文本)配对数据上训练Vision Encoder和Vision Adapter。
-
后训练。采用与文本模型类似的方案,训练Vision Encoder和Vision Adapter:
- 通过多轮监督微调、拒绝采样和直接偏好优化(DPO)进行对齐。
- 利用 Llama 3.1 模型对领域内图像的问题和答案进行过滤与增强,生成合成数据,并使用奖励模型对所有候选答案进行排序,以提供高质量的微调数据。
- 加入了安全缓解数据,在保持模型可用性的同时,产出具备高水平安全性的模型。
Llama 4的主要架构更新:
- 视觉编码器采用MetaCLIP
- 混合专家(MoE)架构: Llama 4 Scout采用17B激活参数、109B总参数、16个专家;Llama 4 Maverick采用17B激活参数、400B总参数、128个专家。
- 早期融合(Early Fusion):
- 视觉编码器与 LLM 联合训练、
- 视觉编码器输出的视觉 token和文本token 从 LLM 的第 1 层起就组成统一的混合序列,共同进入 MoE backbone 的全部 128 层,在每一层都通过统一的 Self-Attention 进行交互
技术影响: Llama系列的开源策略极大地推动了多模态大模型的普及。Llama 4的MoE架构和超长上下文能力代表了开源多模态大模型的最新水平。
5. 模型架构演进分析
视觉-语言模型(VLM)的架构演进是过去五年多模态领域最为核心的发展脉络之一。从早期预训练时代基于BERT变体的双流与单流探索,到统一时代对比学习与融合策略的多元化尝试,再到大模型时代以大型语言模型(LLM)为中心的架构范式的全面确立,每一阶段都留下了深刻的范式烙印。本章将严格基于本报告正文所涵盖的模型,从五个维度系统梳理这一演进过程。
5.1 从双流到单流再到LLM中心的架构演进
VLM的整体架构演进可以划分为三个清晰的阶段:预训练时代的BERT式架构探索期(2019-2020)、统一时代的多元化融合期(2021-2022),以及大模型时代的LLM中心范式确立期(2023-2025)。
5.1.1 BERT式架构的双流与单流之争(2019-2020)
这一时期的VLM深受BERT架构的影响,核心分歧在于视觉与语言模态的融合时机——即"何时融合"(Early Fusion vs. Late Fusion)的问题。
双流架构:延迟融合的代表。 ViLBERT(NeurIPS 2019)是这一范式的典型代表,它采用两个独立的Transformer流分别处理视觉和文本输入,通过共注意力Transformer层(Co-attentional Transformer Layers)实现跨模态交互。这种设计的核心假设是:视觉和语言具有本质不同的模态特性,应在各自充分编码后再进行交叉融合。ViLBERT使用BERT-BASE初始化,参数量达221M。LXMERT(EMNLP 2019)进一步细化了双流架构,提出三编码器结构——语言编码器、物体关系编码器和跨模态编码器——并引入5个预训练任务进行联合训练,参数量183M。双流架构的优势在于模态编码的独立性和可解释性,但其分离的设计也限制了深层跨模态交互的能力。
单流架构:早期融合的探索。 UNITER(ECCV 2020)代表了另一种思路,它将视觉区域特征和文本词嵌入直接拼接后输入单个Transformer,实现早期融合。UNITER引入了条件掩码(Conditional Masking)和基于最优传输的词-区域对齐(WRA),提供了86M和303M两种规模。单流架构的优势在于跨模态信息可以在Transformer的每一层充分交互,但计算复杂度随输入长度显著增长。
OSCAR的折中方案。 OSCAR(ECCV 2020)另辟蹊径,将对象标签作为跨模态的"锚点"(Anchor),通过三元组表示(图像-标签-文本)隐式地桥接两个模态,既保留了一定的模态独立性,又实现了有效的跨模态对齐。
这一阶段的架构选择本质上是对"融合时机"这一核心问题的不同回答,为后续发展奠定了重要的技术基础。
5.1.2 对比学习、多路与解耦(2021-2022)
随着ViT(ICLR 2021)将Transformer引入视觉编码,VLM架构进入了一个多元化发展的统一时代。这一时期的核心特征是:视觉编码器与语言编码器的关系被重新定义,多种融合策略并行发展。
双编码器对比架构。 CLIP(ICML 2021)是这一范式的里程碑,它采用完全独立的双编码器结构,通过4亿图文对的对比学习实现模态对齐,零样本ImageNet准确率达76.2%。CLIP的成功证明了"弱耦合"架构在大规模数据下的有效性。后续SigLIP(ICCV 2023)和SigLIP2(2025)沿用了这一架构,但通过Sigmoid损失替代Softmax损失、引入自蒸馏和掩码预测等技术不断优化。
先对齐后融合:ALBEF。 ALBEF(NeurIPS 2021)提出了一种"先对齐后融合"(Align before Fuse)的两阶段策略——先用对比学习在特征层面粗对齐,再用多模态编码器进行细粒度融合。其动量蒸馏(Momentum Distillation)机制有效缓解了训练数据中的噪声问题。
多路Transformer:VLMO。 VLMO(NeurIPS 2022)提出了MOME(Mixture-of-Modality-Experts)多路Transformer架构,在Transformer的每个前馈层中设置模态专属专家(Vision Expert、Language Expert、Vision-Language Expert),通过分阶段预训练逐步激活不同路径,实现了模态灵活切换。
冻结LLM+轻量桥接:Flamingo。 Flamingo(NeurIPS 2022)代表了一个重要的范式转变——在预训练好的大型语言模型(LLM)基础上,通过轻量的门控交叉注意力密集层(GATED XATTN-DENSE)和Perceiver Resampler实现视觉信息的注入,同时冻结LLM参数。这使得VLM可以继承LLM强大的语言理解和推理能力,仅需少量可训练参数即可实现少样本(Few-shot)多模态能力。
解耦解码器:CoCa。 CoCa(2022)提出了解耦解码器架构,同时包含单模态解码器(仅文本自注意力)和多模态解码器(文本-视觉交叉注意力),将对比学习和生成式目标统一在一个框架中。
统一掩码建模:BEiT-3。 BEiT-3(2022)采用Multiway Transformer架构,将图像视为一种"外语",统一使用掩码数据建模进行预训练,实现了视觉-语言任务的统一处理。
5.1.3 以LLM为中心的全面确立(2023-2025)
2023年之后,VLM架构全面转向以LLM为中心的设计范式——预训练好的视觉编码器提取视觉特征,通过某种桥接机制注入冻结的LLM。这一范式显著降低了训练成本,同时充分利用了LLM的语言理解和推理能力。
| 模型 | 时间 | 架构范式 | 视觉编码器 | 桥接机制 | LLM |
|---|---|---|---|---|---|
| BLIP-2 | ICML 2023 | 冻结LLM+桥接 | 冻结ViT | Q-Former (188M) | 冻结OPT/T5 |
| LLaVA | NeurIPS 2023 | 视觉指令微调 | 冻结ViT | 线性投影 | LLaMA |
| Qwen-VL | 2023 | 冻结LLM+适配器 | 冻结ViT | 单层交叉注意力 | Qwen-7B |
| DeepSeek-VL | 2024.3 | 混合编码器+桥接 | SigLIP-L + SAM-B | 两层混合MLP | 冻结LLM |
| DeepSeek-VL2 | 2024.12 | MoE+动态分块 | SigLIP-SO400M | 动态分块 | MoE+MLA |
| Qwen2-VL | 2024 | 动态分辨率 | 动态ViT (675M) | Patch Merger (两层MLP) | Qwen2 |
| Llama 3.2 | 2024.9 | 门控交叉注意力 | ViT-H/14 | 门控交叉注意力适配器 | 冻结Llama 3 |
| Qwen3-VL | 2025.4 | DeepStack+交错 | SigLIP2-SO-400M | DeepStack + 交错M-RoPE | Qwen3(包括Dense和MoE) |
| Llama 4 | 2025.4 | MoE早期融合 | MetaCLIP | 早期融合 | MoE (17B/400B) |
从架构演进的全景来看,VLM经历了从"何时融合"(双流到单流)到"如何桥接"(对比学习到LLM中心)的范式跃迁。目标检测器驱动的多模态时代关注模态融合的时机与深度,端到端训练融合时代探索了对比学习、多路专家、解耦解码器等多元化方案,大模型时代则全面确立了以冻结LLM为核心、轻量桥接为特征的架构范式。
5.2 视觉特征提取的演进
视觉特征提取模块是VLM的"眼睛",其演进直接影响模型对视觉世界的感知能力。从预训练时代的区域特征到ViT时代的Patch特征,再到动态分辨率和混合编码,视觉特征提取经历了质的飞跃。
5.2.1 从区域特征到Patch特征:ViT的范式革命
区域特征时代(2019-2020)。 预训练时代的VLM(ViLBERT、LXMERT、UNITER、OSCAR)均采用Faster R-CNN提取的区域特征(Region Features)作为视觉表示。具体而言,Faster R-CNN在图像上检测出固定数量(通常为36或100个)的目标区域,每个区域被编码为一个固定维度的特征向量。这种表示的优势在于具有明确的语义对应关系(每个区域对应一个潜在物体),OSCAR正是利用这一特性将对象标签作为跨模态锚点。然而,区域特征也存在显著局限:检测器的训练数据限制导致对超出预定义类别物体的识别能力不足,且区域特征的空间信息相对粗糙。
Patch特征时代(2021起)。 ViT(ICLR 2021)的提出彻底改变了视觉表示的范式——将图像分割为固定大小的Patch,直接输入Transformer进行编码。ViLT(ICML 2021)是首批采用纯Transformer视觉编码的VLM之一,使用ViT-B/32作为视觉骨干,完全摒弃了CNN。Patch特征的优势在于:无需依赖预训练检测器,可以感知图像的任意区域;保留了更细粒度的空间信息;与文本Token的表示形式更加统一,便于跨模态融合。
CLIP(ICML 2021)的成功进一步验证了Patch特征在跨模态学习中的有效性——其视觉编码器正是基于ViT架构。此后, virtually all VLM均采用基于ViT的视觉编码器。
5.2.2 对比预训练 vs 分类预训练:PaLI-3的关键发现
PaLI-3(2023)的实验揭示了一个重要发现:使用SigLIP对比学习目标预训练的ViT,在下游多模态任务中表现优于传统的分类预训练(如JFT分类)ViT。具体而言,PaLI-3使用5B参数规模,采用SigLIP对比预训练的ViT作为视觉骨干,在多项任务上取得了与比它大10倍的模型相媲美的性能,提出"小即是美"(Small Can Be Beautiful)的理念。这一发现对整个领域产生了深远影响——对比预训练能够产生更适合跨模态对齐的视觉表示,因为它直接在图像-文本对上进行优化,而非仅仅学习图像分类的判别特征。
此后,SigLIP系列(SigLIP、SigLIP2)成为VLM视觉编码器的标准选择:DeepSeek-VL使用SigLIP-L,Qwen3-VL使用SigLIP2-SO-400M,PaliGemma系列使用SigLIP/SigLIP2。
5.2.3 高分辨率策略与动态分辨率
随着VLM需要处理越来越复杂的视觉输入(如文档、图表、小物体识别),视觉编码器的分辨率问题日益凸显。
| 策略 | 代表模型 | 实现方式 |
|---|---|---|
| 固定分辨率Patch | ViLT, CLIP, ALBEF | 224x224或336x336,固定Patch大小 |
| 混合编码器 | DeepSeek-VL | SigLIP-L + SAM-B,结合全局与局部特征 |
| 动态分块 | DeepSeek-VL2 | 动态分块(Dynamic Tiling)策略,自适应处理不同分辨率 |
| 动态分辨率 | Qwen2-VL | 675M参数动态分辨率ViT,原生支持任意长宽比 |
| NaFlex | SigLIP2 | 可变分辨率策略,灵活处理不同尺寸输入 |
| DeepStack | Qwen3-VL | 基于SigLIP2-SO-400M的多层特征堆叠 |
混合编码器。 DeepSeek-VL(2024.3)采用SigLIP-L和SAM-B(Segment Anything Model)的混合编码器设计——SigLIP-L提供全局语义特征,SAM-B提供细粒度的局部特征,两者通过两层混合MLP融合,显著提升了模型对细节的视觉感知能力。
动态分块与动态分辨率。 DeepSeek-VL2(2024.12)引入动态分块策略,根据输入图像的分辨率自适应调整分块方式。Qwen2-VL(2024)则更进一步,采用675M参数的动态分辨率ViT,能够原生处理任意长宽比的图像。Qwen3-VL(2025.4)的DeepStack架构进一步增强了高分辨率处理能力。
NaFlex。 SigLIP2(2025)引入了NaFlex(Native Flex)策略,支持可变分辨率输入,使模型能够灵活处理从小图到高清大图的各种尺寸。
视觉特征提取的演进脉络清晰:从依赖预训练检测器的区域特征,到ViT带来的Patch特征革命,再到对比预训练的优越性被认知,最终走向高分辨率和动态分辨率的灵活处理。这一演进使得VLM的视觉感知能力从"识别已知物体"逐步扩展到"理解任意视觉内容"。
5.3 跨模态桥接器的演进
跨模态桥接器(Cross-modal Bridge)是VLM架构中的关键组件,负责将视觉编码器输出的特征转换为LLM可以理解和处理的形式。从预训练时代的复杂融合层到大模型时代的极简投影,桥接器的设计体现了"够用即可"的实用主义演进。
5.3.1 预训练时代的融合层设计
| 模型 | 桥接机制 | 可训练参数规模 |
|---|---|---|
| ViLBERT | 共注意力Transformer层(Co-attentional Transformer) | 221M |
| LXMERT | 三编码器交叉融合 | 183M |
| UNITER | 单流Transformer直接融合 | 86M/303M |
| OSCAR | 对象标签作为隐式锚点 | - |
预训练时代的桥接器本质上是深度多模态融合网络。ViLBERT的共注意力Transformer层允许视觉和语言表示在每一层相互查询和关注,实现深层交互。LXMERT的三编码器结构通过跨模态编码器显式建模两种模态的关系。这些设计的共同特点是:桥接器本身就是模型的核心计算部分,参数量巨大,需要端到端训练。
5.3.2 端到端多模态融合多元架构设计
端到端多模态融合时代出现了多种桥接方案,从完全独立的对比学习到逐渐向LLM中心范式过渡:
- CLIP/SigLIP: 无显式桥接器,完全依赖对比学习在特征空间对齐两个模态
- ALBEF: 对比学习粗对齐 + 多模态编码器细融合的两层桥接
- VLMO: MOME多路Transformer,模态专家作为桥接
- Flamingo: GATED XATTN-DENSE + Perceiver Resampler,冻结LLM注入视觉信息
- CoCa: 解耦解码器中的交叉注意力层作为桥接
- BLIP: MED(Multimodal Encoder-Decoder)统一编码器-解码器架构
Flamingo的设计尤其值得关注——它首次大规模展示了在冻结LLM上通过轻量桥接实现多模态能力的可行性,为大模型时代的架构范式奠定了实践基础。
5.3.3 大模型时代的桥接器设计
大模型时代的桥接器设计呈现出明显的简化趋势,从复杂的融合网络向轻量投影进化:
| 模型 | 桥接器 | 参数量 | 设计哲学 |
|---|---|---|---|
| BLIP-2 | Q-Former | 188M | 查询式信息提取 |
| LLaVA | 线性投影 | ~2M | 极简主义 |
| Qwen-VL | 单层交叉注意力适配器 | - | 轻量适配 |
| DeepSeek-VL | 两层混合MLP | - | 混合特征融合 |
| Qwen2-VL | Patch Merger(两层MLP) | - | Patch压缩 |
| Qwen3-VL | DeepStack + 交错M-RoPE | - | 多层特征堆叠 |
| Llama 3.2 | 门控交叉注意力适配器 | - | 门控控制 |
| Llama 4 | 早期融合 | - | 模态混合 |
Q-Former:查询驱动的信息提取。 BLIP-2的Q-Former是这一阶段的标志性设计。它使用32个可学习的查询向量,通过交叉注意力与冻结ViT的视觉特征交互,然后通过自注意力在查询之间共享信息,最终通过全连接层映射到LLM的嵌入空间。Q-Former的设计哲学是"提取而非转换"——不是将整个视觉特征图映射到LLM空间,而是通过查询机制提取与当前任务最相关的视觉信息。188M的可训练参数在当时的VLM中属于极小规模。
MLP线性投影:极简主义的胜利。 LLaVA采用了最为简洁的设计——单个线性层将视觉特征投影到LLM的词嵌入空间。这一看似过于简单的设计却取得了巨大成功,证明在强大的视觉编码器和LLM基础上,复杂的桥接器并非必需。LLaVA之后,线性投影或其微小变体成为许多开源MLLM的默认选择。
Patch Merger与DeepStack:视觉感知的增强。 Qwen2-VL的Patch Merger(两层MLP)在压缩视觉Patch序列长度的同时保留关键信息,使LLM能够更高效地处理高分辨率图像。Qwen3-VL的DeepStack进一步引入多层特征堆叠和交错M-RoPE,实现了对图像和视频的统一高效处理。
门控交叉注意力:控制与精度的平衡。 Llama 3.2采用门控交叉注意力适配器,通过门控机制控制视觉信息的注入程度,在保持LLM语言能力的同时实现精确的视觉感知。Llama 4的早期融合则将视觉Token与文本Token在输入层就进行混合,代表了另一种极端的设计哲学。
桥接器的演进趋势清晰可见:从预训练时代参数量达百M级别的深度融合网络,到大模型时代参数量从188M(Q-Former)急剧下降到2M级别(线性投影),再到Qwen系列在压缩与感知精度之间寻找平衡。这一演进的驱动力在于:随着视觉编码器和LLM质量的不断提升,桥接器的角色从"复杂融合"转变为"简单适配",核心挑战从"如何融合"变成了"如何高效地将高质量视觉特征送入强大的LLM"。
5.4 训练目标与范式的演进
训练目标是驱动VLM学习的核心动力,其演进反映了领域对"VLM应该学习什么"这一根本问题的认知深化。
5.4.1 预训练时代:多任务掩码学习
预训练时代的VLM继承自NLP的掩码语言建模(MLM)范式,并扩展到多模态场景:
| 模型 | 训练目标 | 特点 |
|---|---|---|
| ViLBERT | MLM + MRM + ITM | 掩码语言建模 + 掩码区域建模 + 图像-文本匹配 |
| LXMERT | 5个预训练任务 | 语言掩码 + 视觉掩码 + 跨模态匹配 + 视觉问答 + 区域描述 |
| UNITER | MLM + ITM + WRA | 引入基于最优传输的词-区域对齐(WRA) |
| OSCAR | MLM + ITM | 对象标签作为锚点辅助训练 |
这一阶段的训练目标以掩码预测(语言Token或视觉区域)和匹配判断(图文是否匹配)为主,目标是学习细粒度的跨模态对应关系。这些目标的设计深受BERT影响,将视觉区域类比为文本Token进行掩码和预测。
5.4.2 端到端多模态融合:对比、生成与蒸馏的多元化
2021-2022年,训练目标的多元化发展达到了顶峰:
对比学习:CLIP的范式革新。 CLIP将对比学习(Contrastive Learning)引入VLM训练,通过最大化匹配图文对的相似度、最小化不匹配对的相似度来学习跨模态表示。CLIP的成功证明,简单的对比目标在大规模数据下足以产生强大的零样本能力。SigLIP进一步用Sigmoid损失替代Softmax损失,解耦了训练对批次大小的依赖。
对比+生成统一:CoCa。 CoCa提出将对比学习和生成式目标(自回归文本生成)统一在一个框架中,通过解耦解码器同时优化两个目标,兼顾了判别能力和生成能力。
动量蒸馏:ALBEF。 ALBEF引入动量蒸馏(Momentum Distillation),使用动量模型的软标签作为训练目标,有效缓解了大规模网络数据中的噪声问题,提升了训练的鲁棒性。
CapFilt:BLIP的数据引导。 BLIP提出CapFilt(Captioning and Filtering)机制,通过编码器-解码器架构生成合成字幕并用过滤器筛选高质量数据,从数据层面而非目标函数层面优化训练效果。
统一掩码建模:BEiT-3。 BEiT-3将所有模态统一视为"Token",采用统一的掩码数据建模目标,简化了多模态预训练的目标设计。
5.4.3 大模型时代:从预训练目标到训练范式
大模型时代的训练不再局限于单一目标函数,而是演变为包含多个阶段的训练范式:
| 模型/技术 | 训练范式创新 |
|---|---|
| BLIP-2 | 两阶段训练:Q-Former先与冻结ViT预训练,再与冻结LLM对齐 |
| LLaVA | 视觉指令微调(Visual Instruction Tuning),将视觉任务转化为指令跟随 |
| BLIP | CapFilt数据引导训练,字幕生成+过滤双模块 |
| DeepSeek-VL | 70/30模态平衡训练,强制保持视觉和语言Token的比例平衡 |
| DeepSeek-VL2 | 动态分块训练 + MoE路由 |
| Qwen-VL | 三阶段训练:单模态预训练 → 多模态预训练 → 指令微调 |
| Qwen3-VL | 四阶段训练:视觉预训练 → 多模态预训练 → 长上下文训练 → 后训练 |
| SigLIP2 | ACID(All-Crop Image-Text Data)数据策展,自蒸馏 + 掩码预测 |
| Llama 4 | 模态混合训练,早期融合 + MoE路由 |
视觉指令微调:LLaVA的范式贡献。 LLaVA(NeurIPS 2023)提出的视觉指令微调是VLM训练范式的里程碑创新。它将传统的VLM预训练-微调范式转变为大模型时代的两阶段范式:(1)特征对齐的预训练阶段,(2)端到端的指令微调阶段。在指令微调阶段,模型学习遵循自然语言指令完成各种视觉-语言任务,极大地提升了模型的交互能力和通用性。这一范式被 virtually all 后续的MLLM所采用。
模态平衡训练:DeepSeek-VL。 DeepSeek-VL发现,在多模态训练中,由于视觉Patch数量通常远多于文本Token,模型容易过度偏向视觉模态。为此,它引入70/30模态平衡训练策略,强制保持视觉和语言Token的比例平衡,确保两种模态得到充分学习。
多阶段训练:Qwen系列。 Qwen-VL的三阶段训练(单模态预训练 → 多模态预训练 → 指令微调)成为VLM训练的标准流程。Qwen3-VL进一步扩展为四阶段,增加了长上下文训练阶段以支持长视频和文档理解。
数据策展:SigLIP2。 SigLIP2的ACID(All-Crop Image-Text Data)数据策展策略代表了训练范式向数据侧的深度延伸——通过为多裁剪图像-文本对提供丰富的训练信号(自蒸馏 + 掩码预测),在数据层面而非模型层面提升学习效果。
训练目标与范式的演进揭示了一个深层趋势:从预训练时代精心设计的多任务目标函数,到统一时代对比学习带来的简化与统一,再到大模型时代训练流程的系统工程化(多阶段训练、数据策展、模态平衡),VLM的训练方法论从"目标函数驱动"逐渐演变为"系统范式驱动"。
综上所述,VLM的架构演进是一个多维度协同发展的过程。在整体架构维度,从双流到单流再到LLM中心,融合时机不断推迟、融合方式不断简化;在视觉特征维度,从区域特征到Patch特征再到动态高分辨率,感知能力持续增强;在桥接器维度,从百M参数的融合网络到M级参数的轻量投影,设计哲学日趋实用;在训练范式维度,从多任务掩码学习到系统工程化的多阶段训练,方法论不断成熟;在数据维度,从百万到十亿的规模跃迁和多语言覆盖的扩展,为模型能力提供了坚实基础。这几个维度的演进相互交织、相互促进,共同塑造了当代VLM的技术面貌。